Note: In 2018 our total yearly uptime reached 99.995% with just 27 minutes of downtime for the whole year. You can check the monthly history of platform uptime starting from July 2017 on the status page.
The key benefit of being responsible for every part of your product is that you're not paying for anyone else's mistakes. This approach, however, loses proponents because the increasing complexity of the industry makes us take advantage of numerous remote services and third-party solutions.

You may have heard of the recent Amazon servers downtime that caused the outage of many services from huge websites to everyday smart home devices. That is why the flespi development philosophy implies the minimum number of open source libraries and the internal development of most software components. And as we expect flespi to become the key backend component for many IoT applications, we are fully prepared to meet the high demand of the market and guarantee 99.9% platform availability.
Check out the flespi service & pricing plan including Service Level Agreement (SLA).

OK, so how do we determine system uptime and how will it affect our clients?
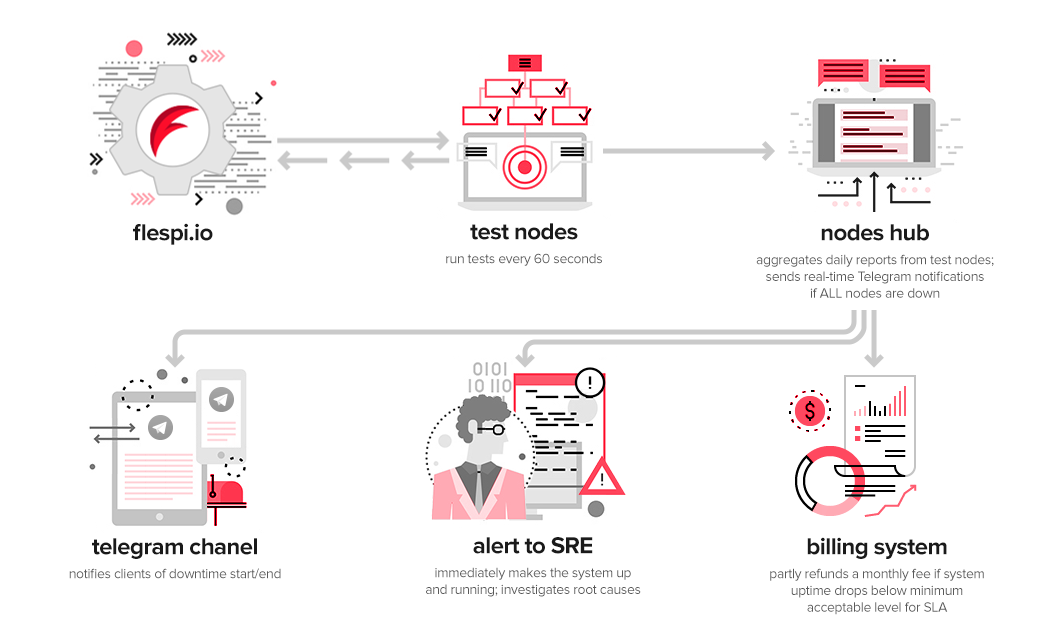
Several remote servers with testing nodes are working separately in different data centers. Each node performs a full gateway and platform functionality test every 60 seconds. The test goes as follows:
- check network state (to avoid the situation when flespi is up but the testing node has no Internet connection);
- read remote channel information (to verify REST API functioning);
- establish a TCP connection to a channel's URL, identify it, and send messages to the channel (to emulate device connection);
- send a command to the established connection and verify its reception on the opened connection (also check that the command moved from the queue to the list of executed commands);
- receive all posted messages from the channels' queue and verify their contents and quantity (to verify messages availability).
The test fails even if only one of its components (1 to 5 above) fails or if 10 seconds have elapsed from the very first operation in the test cycle. In such a case, the node repeats the test every 10 seconds until successful and generates a report to the central hub. At the moment, if all the nodes detect downtime, the central hub alerts the Telegram group of our Site Reliability Engineer (BTW, he set Imperial March as the alert tone for this group, so a couple of downtimes sounded really ominous).

At the same time, the central hub posts automatic downtime start/end reports to the flespi NOC Telegram channel to keep our users informed and prepared for possible questions from their customers.
As of May 2017, monthly platform uptime amounted to 99.95% with short downtime periods caused by intensive non-stop development work. Needless to say that every tiny occurrence of downtime becomes the subject of our thorough internal investigation aimed at finding the root cause and preventing it from happening again.
At the end of each month, the testing nodes hub consolidates the reports from all the nodes and determines common verified downtime periods — the time when all the testing nodes reported a downtime. The result in percent is reflected in the billing system. Now, according to the newly introduced Service Level Agreement the user’s monthly fee will be automatically reduced (by up to 70% for an uptime lower than 99.9% for Premium SLA) if we don't deliver the promised "three nines" of High Availability.
We declare our High Availability promise with confidence and guarantee a partial refund of a monthly fee if the system uptime drops below the minimum acceptable level for your SLA. This way we want to show appreciation for our customers, treat them fairly, and own our share of responsibility.
Our goal is to equip your business with a failure-proof toolkit that will help you maximize profits and build trustworthiness among clients. And since flespi is destined to be at the heart of your operations, we’ll take your troubles personally and will go the extra mile to live up to your expectations. Let’s boost your business with flespi!