We have recently started telling you about our implementation of the MQTT protocol. This article will be talking about the nuts and bolts of the MBUS broker and its performance measurements.
Picking the technology stack
As a result of the diligent investigation, we decided to use the MQTT protocol as the basis for internal communication of the flespi.io components. Then we crystalised the task: develop a distributed MQTT broker with maximum bandwidth.
We implement all components of the flespi platform as microservices with REST API access. MBUS (short for “message bus”) broker is no exception, and aside from access via MQTT protocol, it allows managing sessions via REST API. No MQTT needed to create a topic, subscribe to sessions and start accumulating messages! Each user gets secure, isolated workspace for managing topics.
The MBUS implementation is based on the
If the application serves a network server, its workers apply the SO_REUSEPORT option for concurrent port use. With this option on, the operating system takes care of the connections balancing between workers. Balancing of TCP connections within the network infrastructure is the responsibility of LVS.
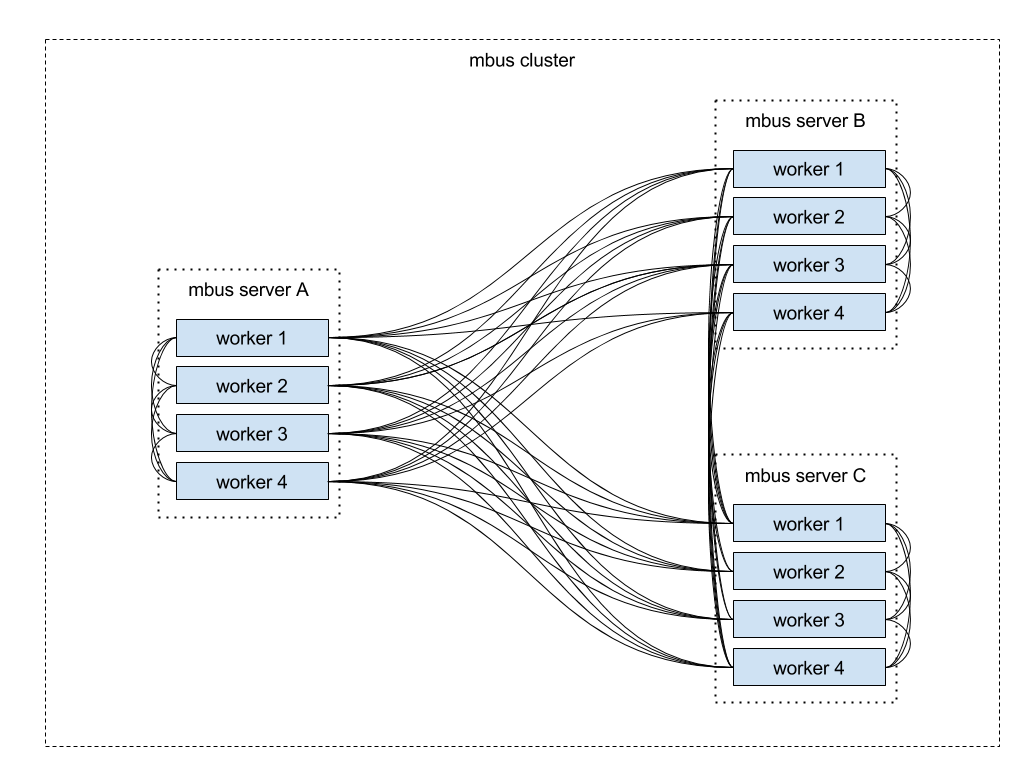
The picture below shows three servers making up a cluster. Each server runs an MBUS process with four workers. Own implementation of the MQ (Messages Queue) protocol provides communication between workers. UDS (Unix Domain Socket) ensures the transport between local workers, and TCP manages the transport between remote workers. All workers share the information about connecting, disconnecting, and subscribing sessions. As a result, each worker is aware which sessions are currently online and which nodes they are connected to.
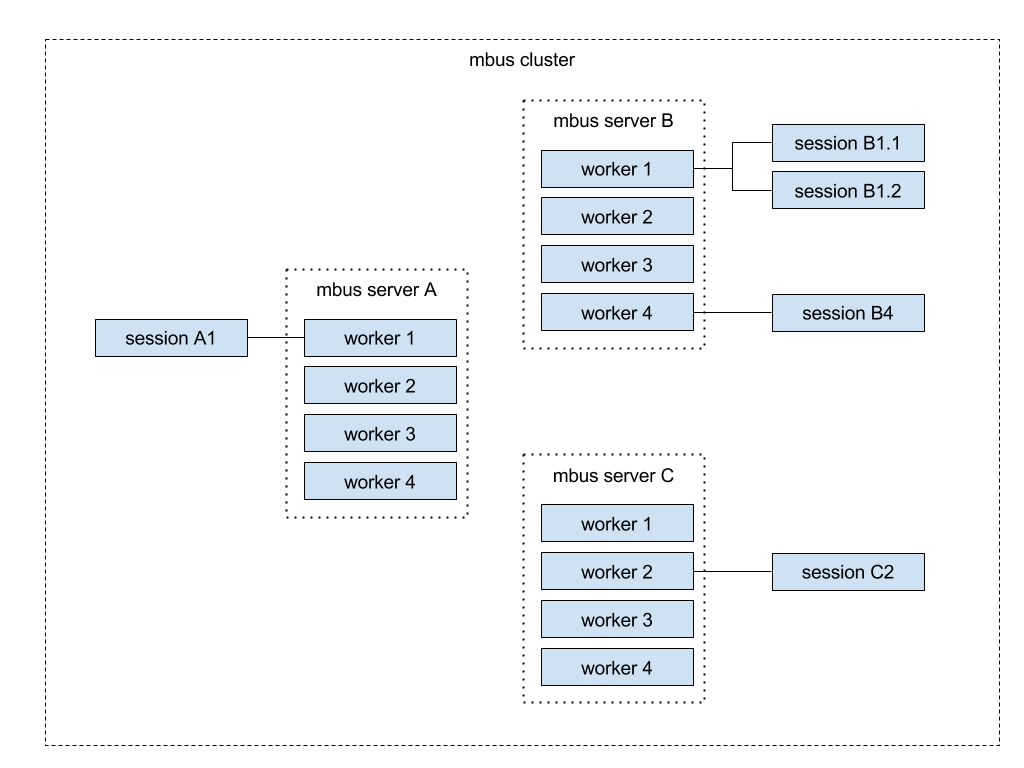
Optimizing the routing job
Let’s now look at the typical MQTT broker task, namely, routing messages. Session A1 generates a massive stream of messages (over 1 million per second) to which sessions B1.1, B1.2, B4, C2 are subscribed.
We could try to solve the task of messages routing the simplest way — the server receiving messages redirects them to each session directly:
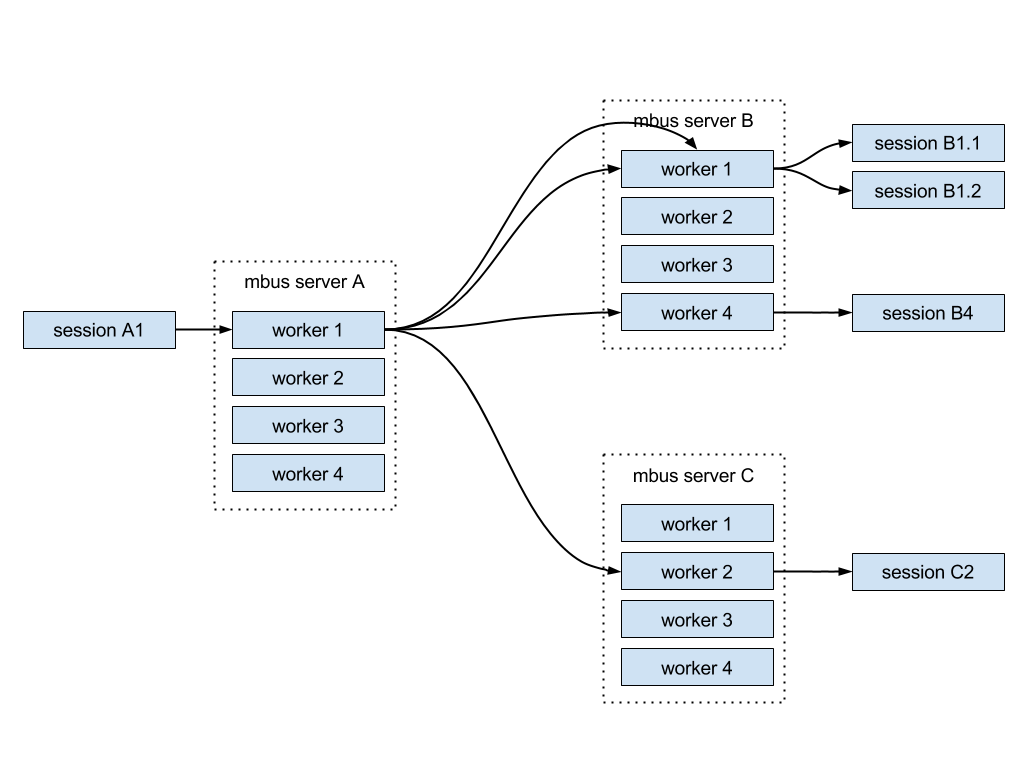
Such approach ensures the quickest message delivery. However, the declared performance will drop proportional to the number of subscribers because each message will duplicate for each session leading to CPU and network bandwidth bottlenecks.
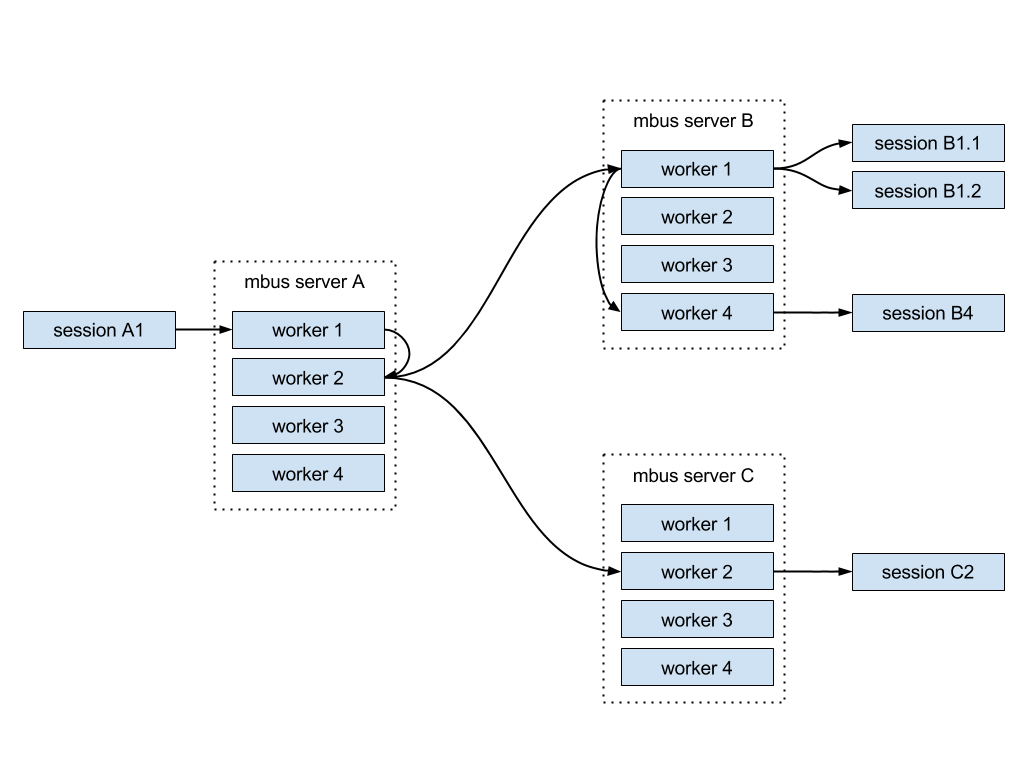
To minimize the effect of the number of subscribers and distribute CPU usage among multiple servers we introduced the following tweaks:
- A worker sends each incoming message only once, regardless of the number of subscribers. This eliminates the CPU bottleneck on the receiving server.
- Other workers picked via a round-robin algorithm ensure the network transfer. This equally distributes the load across all workers.
- If workers on the remote server have several sessions connected to them, messages are transferred over the network only to one of the workers on the server. This way we avoid network bandwidth bottleneck.
- The worker on the remote server sends the message to other local workers.
Here’s the visualization of the described architecture:
Testing MBUS performance
We used the following testing environment:
- MBUS cluster made up of 2 Xeon E3-1231v3 servers, 32GB RAM, 2x1Gb LAN;
- Server with 4 subscribers;
- Server with 8 publishers.
Publishers generate 10,000,000 messages each; therefore, each subscriber has to transfer 40,000,000 messages. The cluster needs to deliver 320,000,000 messages to subscribers.
We visualized the results of testing in
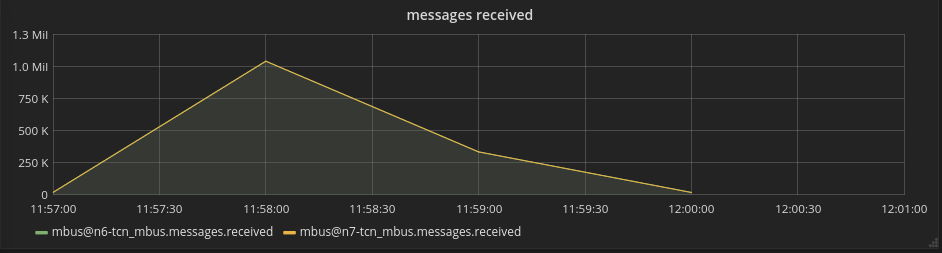
Top messages received: 1,000,000 per second.
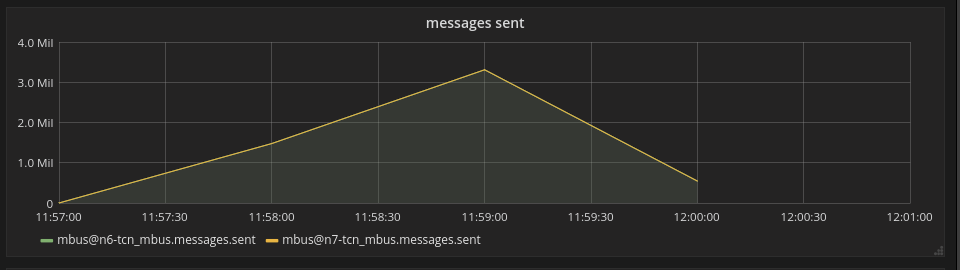
Top messages sent: 3,000,000 per second.
Why do you want to consider using MBUS? Because:
- it’s secure;
- it’s fast;
- it’s universal;
- it works over HTTP and WebSockets;
- it’s free.
Also, it’s well-documented, and we’ll be happy to answer any additional questions you may have.
***
MQTT is an attractive communication option for multiple applications, so we encourage you to look more carefully into the capabilities it offers and match it against the needs of your infrastructure.