- What is PVM?
- AI assistance with PVM
- PVM sandbox
- Main conventions
- Structure of a PVM code
- Atomic syntactic elements of PVM
- PVM value types
- Errors handling at PVM runtime
- Accessing device information
- Control operators
- Math operations
- Distance calculation
- String operations
What is PVM?
PVM stands for Parsing Virtual Machine - special is a programming language to deal efficiently with protocols. Like any programming language, PVM contains syntactical constructions for variables, operators, numbers, string literals, functions, and other abstractions which you may use to define the data transformation algorithm.
PVM was designed to write declarative code. It means that PVM code says not “do this, then that”, but declares “what data we have” and “how it should look at the output”. Data conversion and transformation is a very practical task and the primary reason for PVM existence. Some cases cannot be described effectively with declarative code, that’s why even though PVM code looks declarative, it's still an imperative code. As a result, PVM has a very expressive syntax to declare data format and at the same time, it has variables, loops, conditions, etc. to be able to handle all possible data transformation cases with imperative code.
AI assistance with PVM
We are providing two AI tools to simplify your coding experience with PVM.
The simplest way to explore PVM capabilities is with the help of our AI Assistant (codi). Just open HelpBox by clicking on the CHAT button in top-right corner of your flespi.io account, enable AI Assistant and give it a task to generate some PVM code for you.
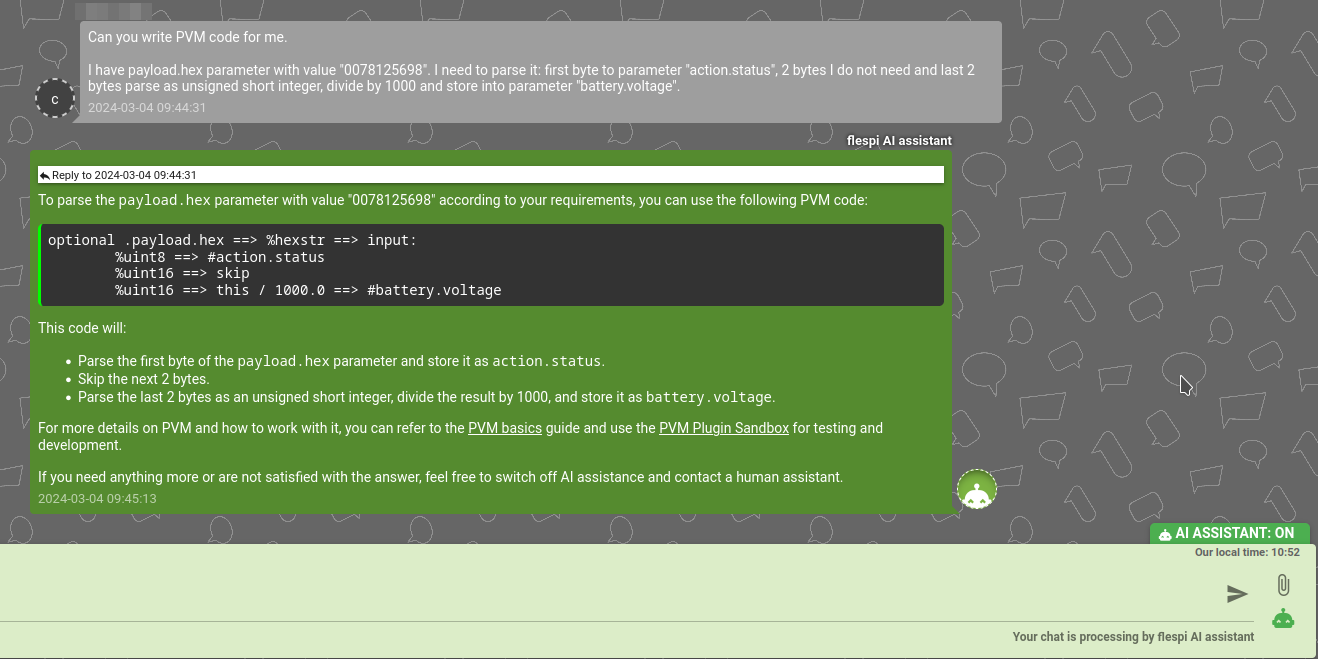
Another option is to use PVM generator tool directly or via API. Click on TOOLS in top-right corner and than select PVM Generator and explain your task. Then click on the "Generate" button and copy generated code into the plugin or sandbox:
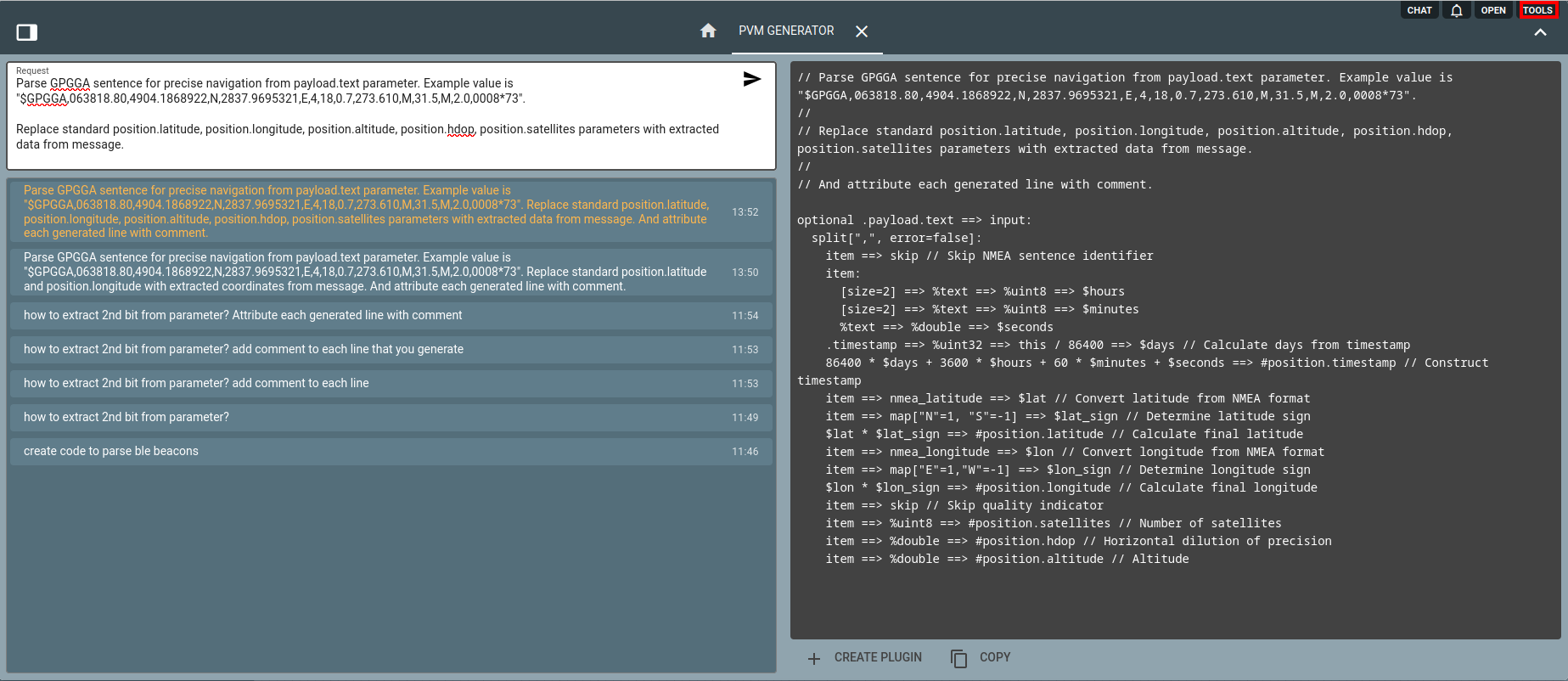
Generated PVM code you may test in PVM plugin sandbox. Sometimes it is wise to split your bigger message transformation task into smaller standalone pieces and feed them into AI separately. However it can be quite capable to provide you with whole big solution sometimes.
PVM sandbox
We have a convenient UI testing tool to experiment with the PVM plugin code: pvm plugin sandbox.
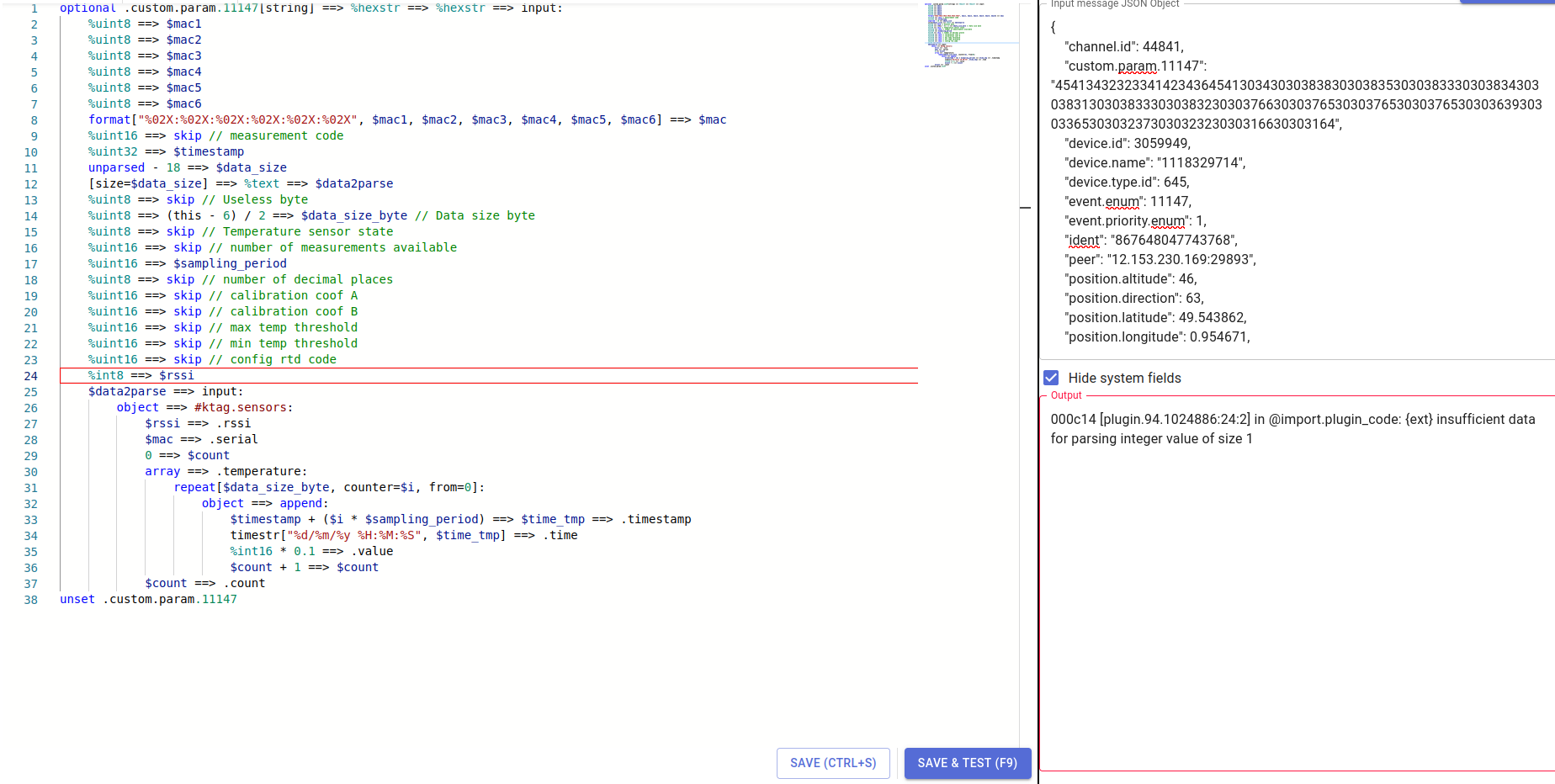
It helps to easily identify errors and detect discrepancies between the the data and the plugin code. This together with our AI assistant should be the primary creating tool and playground for your pvm scripts.
Main conventions
- PVM is a case-sensitive language. unset and UnSet are not the same thing
- Only English symbols can be used as identifiers. Full Unicode support is available only in "string literals"
- Nested elements are separated from the parent with increased indentation (just like in Python), and only horizontal tabulation symbol (0x09 ASCII char, \t) can be used for it
- C++-style comments: /* multiline comment */ and // one-line comment
Structure of a PVM code
Thanks to its declarative look, the PVM code can be treated as structured data in text form (like an XML or YAML file, for example). In other words, the PVM code is knowledge written in structured text form about how data should be parsed and transformed.
Here is the sample of PVM code with comment lines explaining code lines that follow after each comments block:
// take payload.text parameter if present
optional .payload.text ==> input:
// and split by commas,
// in next section each comma-separated element is retrieved with "item ==>" section
split[",", error=false]:
// store first element in sentence_id variable
item ==> $sentence_id
// switch between sentence_id variable values for different action flows
switch[$sentence_id]:
// execution flow when $sentence_id variable value is "$GPGGA"
"$GPGGA":
// ignore second element
item ==> skip
// convert third element from text to double
// and store into message as a parameter position.hdop
item ==> %double ==> #position.hdop
// convert next element from text to 1-byte unsigned integer
// and store into message as a parameter position.satellites
item ==> %uint8 ==> #position.satellites
// next is kind of constant and check
// expected that next element will always be "M",
// if not - plugin will generate parsing error
item ==> <"M">
// remove parameter payload.text from the message
unset .payload.text
// initialize variable variable1 with zero value
0 ==> $variable1
// parse hex string stored in parameter can.data.frame.1 as a binary
// hexadeciam string from value will be loaded into binary bufer with %hex transformer
// and then contents of this binary buffer will be parsed as bits
optional .can.data.frame ==> %hex ==> bits:
// skip first 8 bits
8 ==> skip
// store next 16 bits into variable variable1
16 ==> $variable1
// store value of next 4 bits multiplied by 100 into message parameter named voltage
4 ==> this * 100 ==> #voltage
// format value in $variable1 value as hex string and store into parameter data.version
format["V-%x", $variable1] ==> #data.version
// extract 4 bits from parameter din
// and store as boolean into separate parameter for each digital input
// with name din.X where X is from 1 to 4
optional .din ==> bits:
1 ==> %boolean ==> #din.1
1 ==> %boolean ==> #din.2
1 ==> %boolean ==> #din.3
1 ==> %boolean ==> #din.4
More samples of how PVM code looks like you may find in KB and blog tagged with pvm.
Atomic syntactic elements of PVM
Below is a list of common syntactic elements used to denote atomic parts of the pvm code, like variables, numbers, string literals, etc.
- Number: For example, 0, 1, -100, 3.14, 0x42
- String: One of "string literal", `fixed string literal`
- Binary: One of <"binary string with zero byte" 00>, <01 0203>
- Constant: One of true, false, null
- Word: For example, if, switch, repeat, any_word_without_spaces, pvm4parsing, camelCaseWord
- Variable: For example, $var
- Property: For example, .fixed_property.name
- Property with variable name (aka varprop): For example, {$property_name}
- Type: For example, %uint32
- Parameter: #position.latitude
- Attribute: [key="value", 2, 3, error=false]
- Label: @label_word
Escapes in string literals
String values in PVM can contain binary data, so special rules applied to string literals to encode any byte in string value.
A standard rule to encode any byte: prefix \x followed by two HEX characters in uppercase or lowercase. For example, sequence \x30 encodes byte 0x30 (48 in decimal), which is a zero character (0).
Additional escape sequences can be used to encode well-known control characters: \n, \r, \t, \a, \b, \v, \f.
PVM value types
The PVM basic value types are based on JSON basic types:
- number to operate with numeric values
- string to contain fixed text or binary information
- boolean to denote a true or false value
- null to denote special null value in JSON
- JSON - JSON object or array
One of the main PVM tasks is to parse binary data, and the double value type used by device message JSON for numeric types lacks the accuracy to represent all possible 64-bit integer values as only first 53-bit are available. To overcome this limitation in device messages such 64-bit parameters should be represented as hexadecimal strings during the initial parsing of device message in flespi channel.
Errors handling at PVM runtime
One of the primary tasks of the PVM is data processing and transformation. To effectively handle such tasks, the PVM runtime environment performs strict checks, and any error condition immediately halts code execution. This "fail fast" design approach helps minimize the risk of producing incorrect or inconsistent data.
Runtime errors never occur silently.
For example, comparison operators (<, >, <=, >=) require both operands to be of the same type. No implicit type conversions are ever performed. This removes ambiguity when comparing values of different types, such as a number and a string. As a result, developers writing PVM code must explicitly check or convert value types before performing such operations.
Similarly, attempting to access a missing property of an object or an element of an array results in a runtime error. If an object field or array index might be missing, the developer must use the is_set or optional operator to handle the condition appropriately.
The same rule applies to variables ($variable) that are set conditionally. Attempting to retrieve the value of an unset variable triggers a runtime error. Therefore, if a variable may not be set, the is_set or optional operator must be used before accessing its value.
Accessing device information
To get device's id, cid, type id, and executing plugin id and cid, there are dedicated words:
device.id ==> ...
device.cid ==> ...
device.type.id ==> ...
plugin.id ==> ...
plugin.cid ==> ...
Those fields will be always available and set in PVM plugin code.
There are additional fields which value can be not set (unset) in certain cases, so use optional ... operator to access them:
optional device.type.name ==> ...
optional device.type.title ==> ...
optional protocol.id ==> ...
optional protocol.name ==> ...
In addition, some of those fields are available as a standard message parameters:
.device.name ==> ... // gets device name
.device.id ==> ... // gets device id
As shown above, you can use property access syntax at the initial indentation level to access them.
Device ident value is available as a message parameter too, accessible with property access syntax and with param access syntax:
.ident ==> ...
#ident ==> ...
It's always better to use param access syntax ( #ident ==> ... ) as it's available everywhere in plugin code, even when you parse other object and property access syntax is addressing object other than device message.
Please note that in plugins, device.type.id always shows the id of device's type for which plugin code is executed. And there are a standard message parameter "device.type.id" which shows an effective device type that was used during message parsing. In some protocols, that send their device model name, message parameter "device.type.id" can be different with specified in the flespi device entity.
You may also access advanced device state like current values of device settings, device telemetry or metadata.
PVM code sample accessing device telemetry to detect when parameter value has been changed:
// take from device telemetry last known value of engine.ignition.status
// and add to message new parameter engine.ignition.changed if its value is changed
if optional #engine.ignition.status != optional telemetry[#engine.ignition.status]:
// param in the message is not equal to its last known value
true ==> #engine.ignition.changed
// Here is an advanced example demonstrating check for the message timestamp,
// required if your device can send messages from the black box/history:
if is_set #engine.ignition.status && optional telemetry[#engine.ignition.status].timestamp < #timestamp:
// we have "engine.ignition.status" parameter in current "fresh" message (not from black box)
if #engine.ignition.status != telemetry[#engine.ignition.status]:
// param in the message is not equal to its last known value
true ==> #engine.ignition.changed
PVM code accessing device metadata:
// store metadata value under 'field' to message parameter param.name
optional metadata["field"] ==> #param.name
if is_set metadata["field"]:
... // code will be executed only if field are set
if optional metadata["field"] == 42:
... // code will be executed only if field are set to value 42
PVM code accessing device settings:
// store setting value of named setting settingname
// with field 'field' to message parameter param.name
optional :settingname.field ==> #param.name
if is_set :settingname.field:
... // code executed only if setting field is set
Control operators
Despite the declarative look, PVM is an imperative programming language, executing its code from the top to bottom, and every chain from the left to the right (in the direction of the ==> arrows). Programmers need operators to control execution flow — condition and loop.
Condition
There are two operators for condition — if and switch. Both of them require writing a new section in code to work. Here is an example of the if operator:
if <condition>:
<actions-if-...>
<...-condition …>
<...-becomes-true>
Of course, there are an else and else-if (elif) branches for multiple conditions:
if <condition-1>:
<actions-if-condition-1-becomes-true>
elif <condition-2>:
<actions-if-condition-2-becomes-true>
...
elif <condition-N>:
<actions-if-condition-N-becomes-true>
else:
<actions-if-all-conditions-becomes-false>
There might be any boolean-resulting expression in place of <condition>, as in any general-purpose programming language. For example:
if .temperature < 0:
"Sub-Zero" ==> #wins
Boolean variables can be also used:
.property[boolean] ==> $variable
...
if $variable:
"property is true" ==> #answer
Note that there is no implicit types conversion to boolean. Unlike JavaScript and C/C++, 0 and "" (empty string) will not be treated as false values. There is no "falsy"/"truthy" concept in PVM.
The switch operator can also be used as a special form of the conditional operator. It’s usable when you have one value and many variants of action to do depending on that value:
.property[number] ==> $property
switch[$property]:
1:
<actions-if-$property-is-1>
2, 3:
<actions-if-$property-is-2-or-3>
7 ... 10:
<actions-if-$property-is-from-7-to-10>
default:
<actions-for-all-other-values-of-$property>
Note that every switch case is obvious and can be represented with a set of possible values, or even with a range. The default branch is optional.
Loop
Out practice has shown that one kind of loop operator is enough in most cases. In PVM it’s a repeat[N] placed in the section subject. It repeats the code in section N times. N can be any expression with number type:
repeat[$count]:
<loop-body-repeated-$count-times>
In addition to N, you can specify a counter-variable that will be incremented automatically for each iteration and its starting value:
repeat[$count, counter=$i, from=1]:
<loop-body-repeated-$count-times>
The repeat loop operator has a special form in the binary context (when you parse binary data). It will be covered in the next article.
Value mapping operator
It's very common for PVM code to map one value into another (for example, error codes into text descriptions). To do so there are a map operator. Here is a generic syntax:
.input.value ==> map[<value1>=<replace1>, <value2>=<replace2>, ...] ==> #output.param
And a real example:
optional .event.code.num ==> map[0="MIL State Change", 1="Generic DTC alert"] ==> #event.code
In this example the value 0 of the initial parameter will be replaced with string "MIL State Change" and stored in the event.code parameter, and different input value 1 will be replaced with string "Generic DTC alert" for that parameter.
In the mapping table, all source values has to be of the same type.
Please note that input value XXX which is not listed in the mapping pairs table (aka unknown value) will cause a pvm runtime error with "unexpected value XXX" text. To avoid this you have several mutually-exclusive options:
- pass unknown value as is - by adding mapping pair keep=true
- skip unknown value and the whole processing after the map operator - by adding mapping pair error=false
- replace unknown value with some default - by adding mapping pair default=<value>
If your mapping table is relatively big, you can write map operator in a section form like this:
.input.value ==> map ==> #output.param:
<value1> ==> <replace1>
<value2> ==> <replace2>
...
And options like keep=true has to be written in form keep ==> true on separate lines.
Math operations
Along with basic arithmetic operators like + - * / you can use following mathematical functions:
math.round, math.floor, math.ceil, math.abs, math.acos, math.asin, math.atan, math.cos, math.exp, math.log, math.log2, math.log10, math.sin, math.sqrt, math.tan, math.trunc, math.pow[...]
Here's an example of how to apply these math functions in PVM code:
.battery.level ==> math.round ==> #battery.level
.value ==> math.pow[.power] ==> #value_in_power
When dealing with number values, PVM stores them as int64_t, uint64_t or double type. When you write a constant number value in source code, the way how it's written is important.
If it's written as decimal value without fractional part (as integer), then values from -9223372036854775808 to 9223372036854775807 will be stored internally as number value with int64_t type.
If you write number which is outside of that range, or it's written with fractional part (even with zero fractional part), then it will be stored internally as number value with double type.
For example:
10 ==> $var // stored as int64_t
10.0 ==> $var // stored as double
This is particularly important when performing division operation - operator / will implicitly do an integer division (discarding fractional part) in case both of its operands are integer values.
For example:
3 / 2 ==> #result // {"result": 1}But in most cases you use usual (not integer) division.
Thus if you don't need integer division and one of the division operands written as constant number value, it will be a good practice to always write that number with a fraction part (even if it's zero).
For example:
3 / 2.0 ==> #result // {"result": 1.5}
3.0 / 2 ==> #result // {"result": 1.5}
3.0 / 2.0 ==> #result // {"result": 1.5}Distance calculation
There are few functions to calculate a distance (in kilometers) between coordinates.
1. Between two points given as (latitude, longitude, altitude) or just (latitude, longitude) coordinates:
distance[<lat1>, <lon1>, <alt1>, <lat2>, <lon2>, <alt2>] ==> <number>
distance[<lat1>, <lon1>, <lat2>, <lon2>] ==> <number>
2. Between position of the message and specific point given as (latitude, longitude, altitude) or just (latitude, longitude) coordinates:
distance_to[<lat>, <lon>, <alt>] ==> <number>
distance_to[<lat>, <lon>] ==> <number>
Position of the message is treated as parameters position.latitude, position.longitude, and position.altitude.
3. Between position of the message and last device position in telemetry:
distance_last ==> <number>
In last two cases, if there are no position.latitude and position.longitude parameters in the current message, error will be thrown. Additionally, error will be thrown in last case (distance_last) if device telemetry does not contain last value for position.latitude and position.longitude parameters too.
To avoid throwing error in that case, you can use is_set or optional operator in such a way:
if is_set distance_to[...]:
distance_to[...] ==> <result>
// OR just
optional distance_to[...] ==> <result>
if is_set distance_last:
distance_last ==> <result>
// OR just
optional distance_last ==> <result>
In all cases, if you denote coordinates without altitude, then it will not participate in the calculation for the second point (in message or telemetry) too.
String operations
String transformation
PVM supports several string transformation functions. Some of them does not require any additional arguments to work:
strescape, lowercase, uppercase
Just use them in the chain middle like this:
.payload.text ==> lowercase ==> #payload.text.in.lowercase
Please note that lowercase and uppercase work only for ASCII-letters.
Next transformation functions can be used to trim white-space or any other 1-byte symbol from the string:
trim, trimleft, trimright.
Here is an example of their usage:
.payload.text ==> trim ==> #payload.text.trimmed
.driver.id ==> trimleft["F"] ==> #driver.id.without.leading.f
.payload.text ==> trim["0"] ==> #without.zeros.from.both.sides
Substring replace
Substring replace can be performed with function replace[<what>=<which>].
For example, to replace char "+" with "-" use following pvm code:
.payload.text ==> replace["+"="-"] ==> #payload.text
To remove only first occurrence of the substring "foo" you can add option max=1:
.payload.text ==> replace["foo"="", max=1] ==> #payload.text
You can specify several replace pairs like in the code below:
.payload.text ==> replace["foo"="bar", "baz"="quux"] ==> #payload.text
In this case replace will be performed sequentially - all occurrences of "foo" will be replaced with "bar", then all occurrences of "baz" with "quux", and so on for all specified pairs. In this multiple-pair mode there is no way to specify max=... argument.
Substring extraction
Substring extraction can be performed with function substring in one of two forms: substring[offset=X, size=Y] or substring[start=X, stop=Y]. In all cases, offset, start and stop are zero-based byte indexes, and can be negative. Negative indexes will be automatically normalized relative to the string end position. stop indicating the last non-inclusive byte index of the substring to extract. size indicating the extracted substring size in bytes. Some arguments can be omitted, defaults for offset and start is 0, and for size and stop is the string length.
Here are some examples:
"0123456789" ==> substring[offset=1, size=3] ==> #sub // "123"
"0123456789" ==> substring[size=3] ==> #sub // "012"
"0123456789" ==> substring[offset=-3, size=3] ==> #sub // "789"
"0123456789" ==> substring[start=1, stop=4] ==> #sub // "123"
"0123456789" ==> substring[start=7] ==> #sub // "789"
"0123456789" ==> substring[start=-3] ==> #sub // "789"
"0123456789" ==> substring[stop=-3] ==> #sub // "0123456"
Abort message registration
Message registration can be aborted by using special cancel word.
For example, if you want the messages with position.valid=false parameter not to be stored in the device messages database:
if .position.valid == false:
cancel