In the initial days of October 2023, I found myself on a week-long vacation with my 10-month-old son, termed as a short paternity leave. It was just him and me for an entire week, marking his first experience without his mother present. I made a deliberate choice to power down my PC, silence all chats, and devote my complete attention to the child. Despite my intent to remain disconnected for a full seven days, I managed only the first four days in a digital blackout.
During a quiet moment when my child was nearby exploring, I switched on the TV and typed "Computer Science Conference" into the search box, seeking for something to listen as a background. The stream began with a Cybersecurity conference where some guys discussed their exploits in cracking vacuums and door locks. Eventually, the conversation transitioned to ChatGPT and how to prompt-engineer it. Though I can't recall the specifics of what that guy said on YouTube, the concept seemed surprisingly approachable, and I decided to give it a try.
The following morning, while my son was still immersed in his peaceful baby dreams, I powered up the computer, registered an account at OpenAI, and commenced my experiments. I utilized each moment of his slumber to experiment with generative AI. I had already forgotten the moment I had experienced such sheer enjoyment and excitement.
Initially, I wanted to categorize discussions, distill summaries, and offer basic internal services—a mere trial. Within two months, however, this experiment evolved into a fully functional AI assistant system operating within flespi, aiding us and our users in resolving complex problems.
It’s like an onion. You start with something elementary, use it to build a functional layer, and then employ this newly created layer to introduce yet another, each adding a new piece of functionality. The cycle continues endlessly, with each new commit yielding better and better results, albeit up to a certain point, of course.
In mid-December 2023, following several internal tests, we made the strategic decision to transition our AI assistant from an in-house tool to a user-activated feature. It is integrated into our standard chat-based communication system, called HelpBox from the user's perspective and Teambox from the flespi team's end. Users now can enable or disable AI assistant responses with a click on the corresponding button.

How it works
Once activated, our AI assistant a.k.a. 'codi' (internally abbreviated from Co-Dispatcher), scans discussions to determine if a conversation has concluded with a user's message. If so, codi leverages chunks of knowledge retrieved from our Knowledge Base and relevant Blog articles, matching the conversation's summary and message context, and attempts to generate a suitable response for the user.
It performs exceptionally well when discussing flespi or telematics-related topics—be it technical, commercial, or even marketing inquiries. It delivers satisfactory answers to approximately 85% of consultant-grade questions and occasionally even assists in programming tasks. Let me showcase a few examples of its responses derived from actual conversations before diving into its architecture and providing insights to create a similar AI assistant.
Here, it assisted the user in fixing an incomplete message from a device:

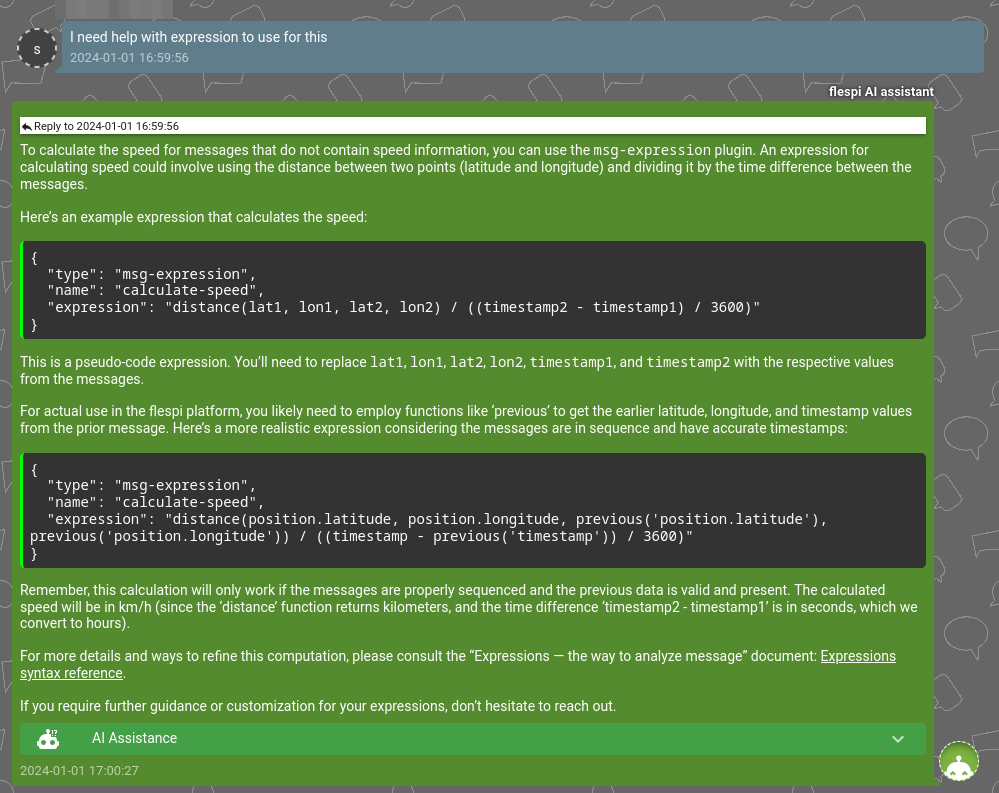
Additionally, it helped the merging of data from satellite and LTE channels into a single device in AWS:

It demonstrates profound knowledge in analytics, sometimes even surpassing flespi engineers' understanding in certain cases:

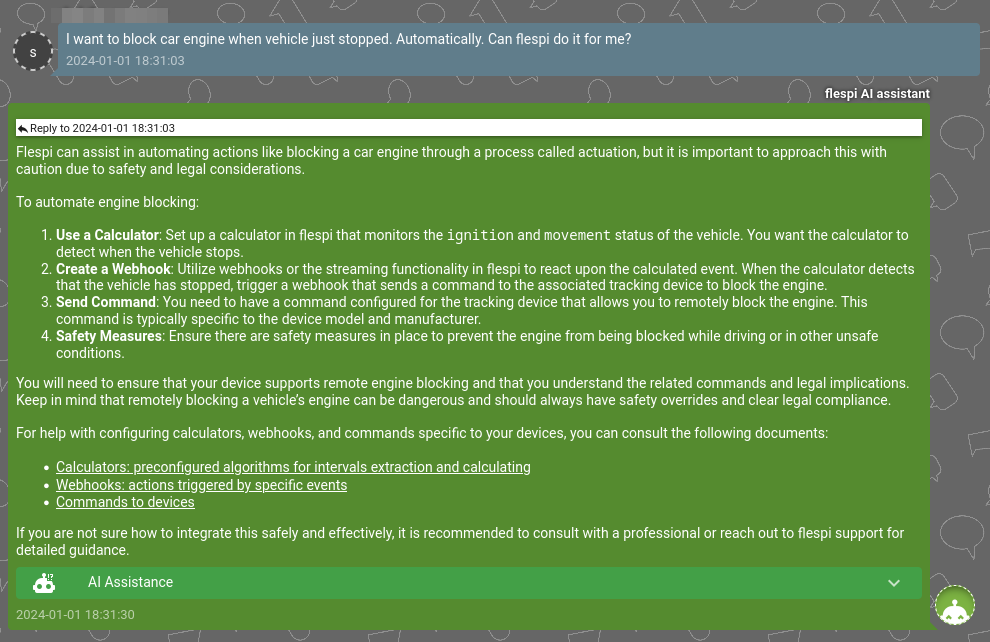
Moreover, it combines various flespi components to propose comprehensive solutions to problems:
Impressively, it offers suggestions for specific trackers, primarily based on content from our blog:

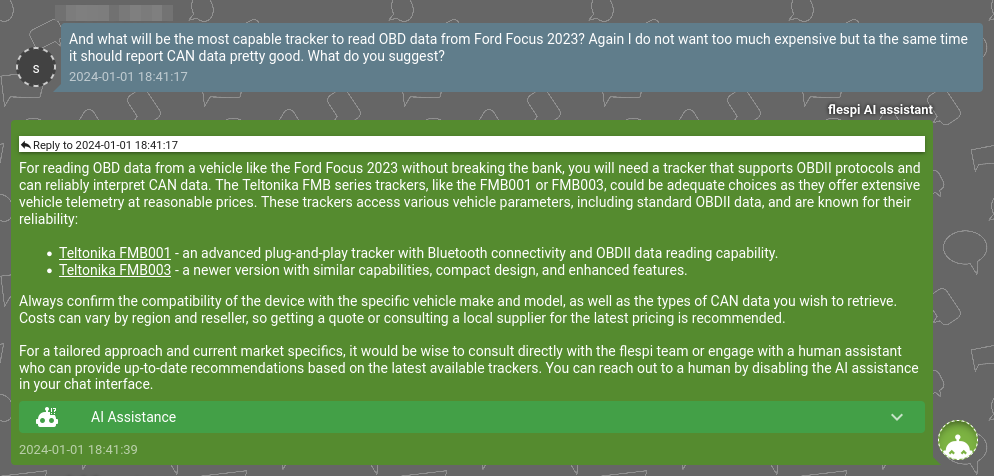
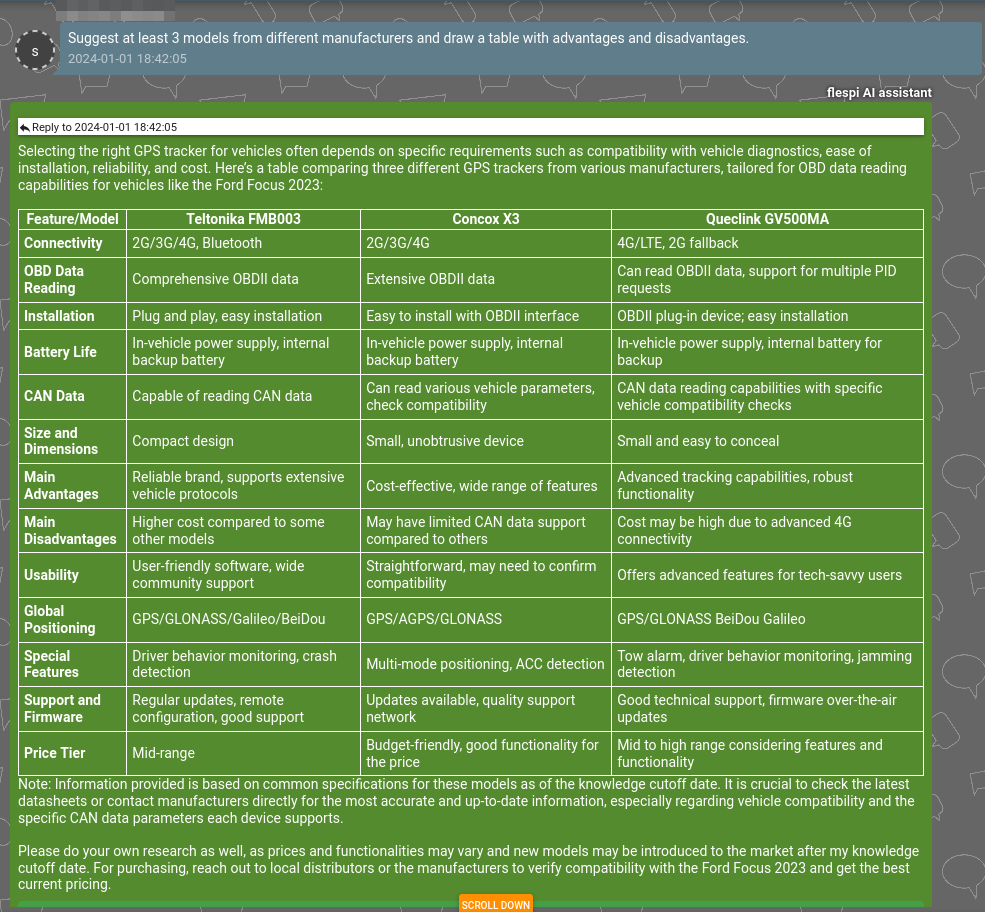
While I have numerous other samples, I encourage you to try it out yourself. Simply log in to or create a free flespi.io account, click on the ‘Chat’ button in the top right corner, select the ‘AI assistant’ button, and have some fun. ;)
Implementation in detail
Our AI assistant relies on the OpenAI platform and currently utilizes the gpt-4 model for generating answers and scanning images accompanied by gpt-3.5-turbo model for contextual discussion and chat summary retrieval. All the magic happens in the prompt content enriched with knowledge related to the question. This is what amplifies the Large Language Model's intelligence and focus (further, I’ll be using the term ‘LLM’ for the API endpoint generating chat completion).
When we say 'knowledge,' we refer to textual content sourced from our Knowledge Base and blog articles, segmented into simple chunks (ranging from 200 to 5,000 characters each) and stored in the Weaviate vector database. Whenever we need to generate an answer on a specific topic, we query the Weaviate database and retrieve text chunks relevant to the subject, preloading them into the chat completion API call. The schema of this operational flow is outlined below:
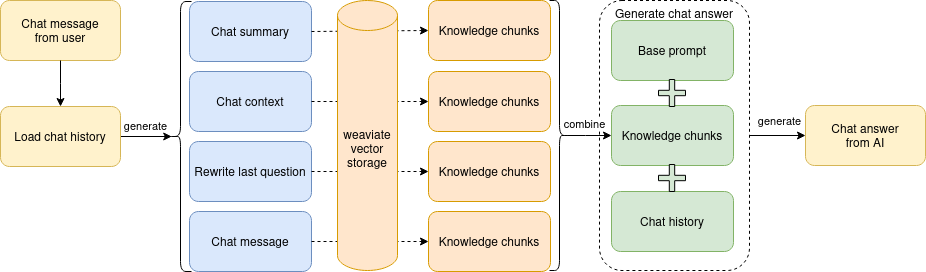
This technique is called Retrieval Augmented Generation (RAG), and here’s a good article describing the way how to apply it on your own data. RAG is easy to implement but it relies heavily on the initial knowledge chunks - their size, quantity supplied to LLM, and how well their content aligns with the discussion's topic. This pivotal aspect drives the entire process. I emphasize once again—the quality of AI responses significantly hinges on the quality of textual content and how it’s been split into chunks.
How to improve text content quality
The initial step is to improve the quality of your text content. This process implies how distinctly your documentation is structured, regardless of whether it's product-related or describes company processes. Here are some insights derived from our experience on restructuring documentation to align with AI-readiness:
Focus on "How To" articles over Reference guides, crafting concise, problem-oriented content. While brief explanations of concepts are also necessary, “How-to” articles solve a user problem and this kind of content should be the main objective for your writers.
Structure articles coherently with headers and paragraphs. Text splitters will use your structure to break content into smaller chunks. The more paragraphs you create - the more streamlined and logically correct chunks you’ll get.
When mixing information between images and text, ensure images are for human understanding, while annotating text briefly for AI comprehension.
Cross-link articles but do it wisely. AI will share them with users in its replies.
English suffices. Feed AI knowledge in English, and it will respond correctly in the same language used by the user during chatting.
AI, especially OpenAI models, comprehend and generate markdown. If your documentation platform natively supports markdown, it's advantageous. However, plaintext chunks are also pretty informative for AI.
Avoid content duplication to prevent bloating of the vector database. Instead, enhance "How To" articles with additional steps to guide both AI and users in the subsequent actions.
How to split information in chunks
In the realm of LLM operations are based on tokens. A token is a unit that can represent a part of a word, but for simplicity, you can consider each individual word as a token. The thing is that you are always limited by the number of tokens you may supply to LLM. The context windows are the current battleground between LLM suppliers.
The more tokens you supply in one completion operation, the more intelligent the model becomes. To give you a picture of how many tokens are available to you in the prompt - Initially released gpt-3.5-turbo model permitted only 4K tokens, whereas recent models like gpt-4 and gpt-4-turbo allow up to 8K and 128K tokens, respectively. For further insights into token limits in OpenAI models, refer here.
That’s why we need to split all documents into smaller parts (chunks) and load them into the chat context when required. The optimal chunk size, approximately 1,000 characters, was determined based on my experiments with flespi-related content, although this greatly depends on your documentation style and the content it offers.
There are lots of tools that can split text content into chunks. The basic tool (a very generic one) is accessible via Python and relies on Beautiful Soup 4 HTML scraper, retaining the textual representation of HTML pages. I scanned this article, and a BS4-based splitter using RecursiveCharacterTextSplitter(chunk_size=1024, chunk_overlap=100) generated three chunks of knowledge:
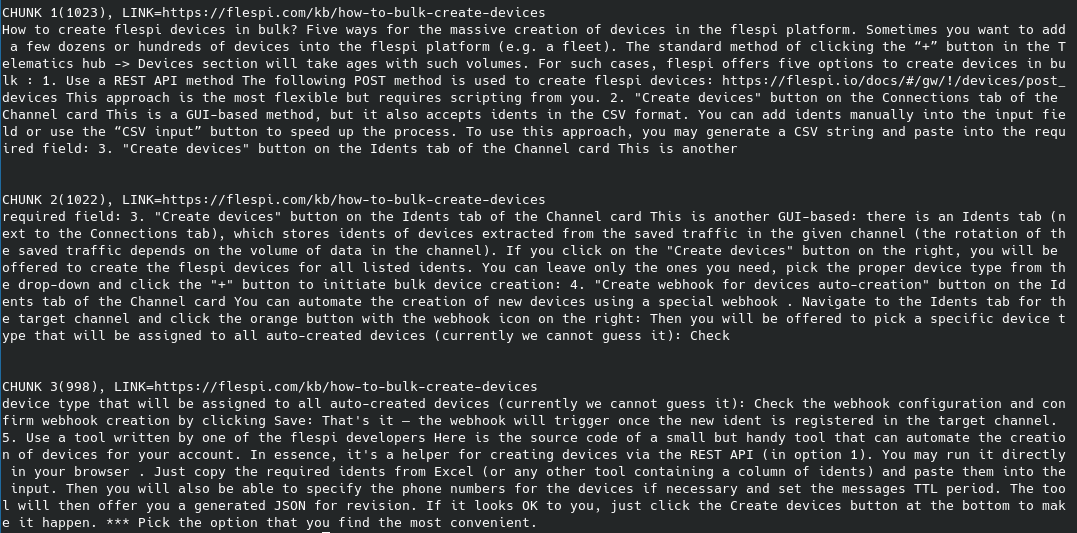
Compare these chunks with the original page. Essentially, this information is what LLM requires to gain intelligence. It constructs logic blocks and comprehends text meaning from these raw character streams.
Such text chunks formed the bedrock of our knowledge system v1. Subsequently, we developed a more sophisticated data-splitting system to enhance AI responses. That’s why we’ve implemented our own splitter, capable of handling larger chunks of related text, more aligned with our KB articles markup. Here are the results obtained from the same page but with our in-house splitter:
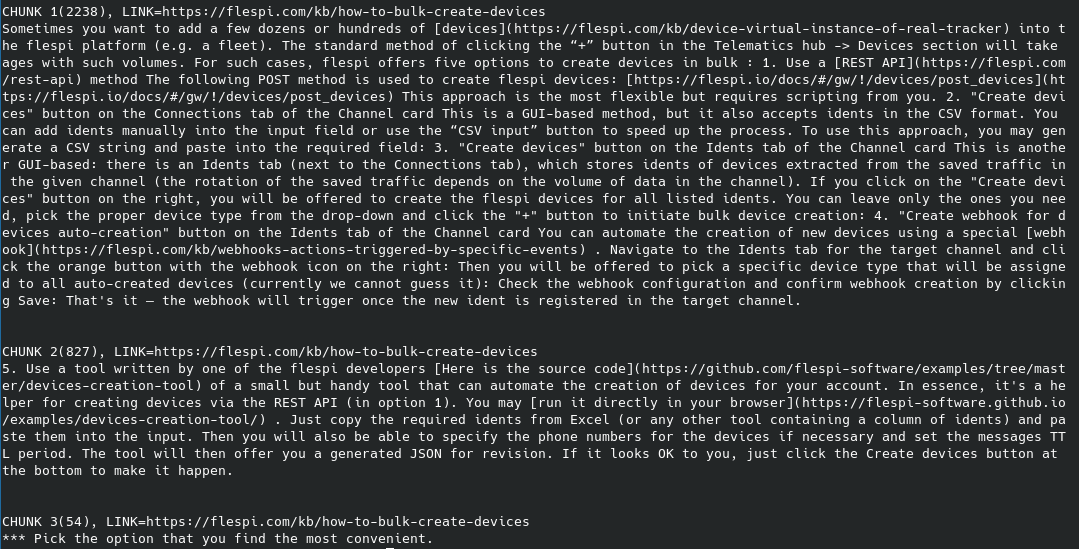
As you can see, it generated entirely different text chunks, grouping text based on logical meanings. The third chunk, however, might be considered an outlier, unlikely to be retrieved from the vector database. Pay attention to the links—we generate them in valid markdown syntax, understood and shareable by LLM in its replies.
You can provide LLM with not just HTML pages but a wide array of documents—CSV, text, Word, PDF, and hundreds of other content systems. Refer to LangChain for document loaders and integrations for more information.
Knowledge retrieval and supply
Upon a user posting a message to a chat with the AI assistant enabled, we retrieve the last 20 messages sent within the last 7 days. LLM is instructed to extract a summary, context, and rephrased question from these messages.
To effectively interpret flespi-specific terms, we created generic flespi information, which is passed to LLM as a system message. Currently, this comprises 16 lines of concise information about flespi and its systems. This fundamental knowledge vastly enhances LLM's informativeness and accuracy during chat summary generation operations.
Once we have the chat summary, chat context, last question rephrased, and the user's original message we now request related knowledge chunks from the Weaviate database. We query chunks separately from the KB and blog because our Knowledge Base is always in actual status compared to the blog articles that may be outdated, spanning six years of flespi development.
Each chunk of knowledge contains a semantic distance measurement relative to the text context queried. Lower values are indicative of better alignment with the text context, with values below 0.15 considered rather adept at describing the context. Values above 0.22, on the other hand, tend to stray further from the context. For instance, here's a list of chunks retrieved from Weaviate when the context text is "Receive device messages via MQTT" (40 chunks were returned):
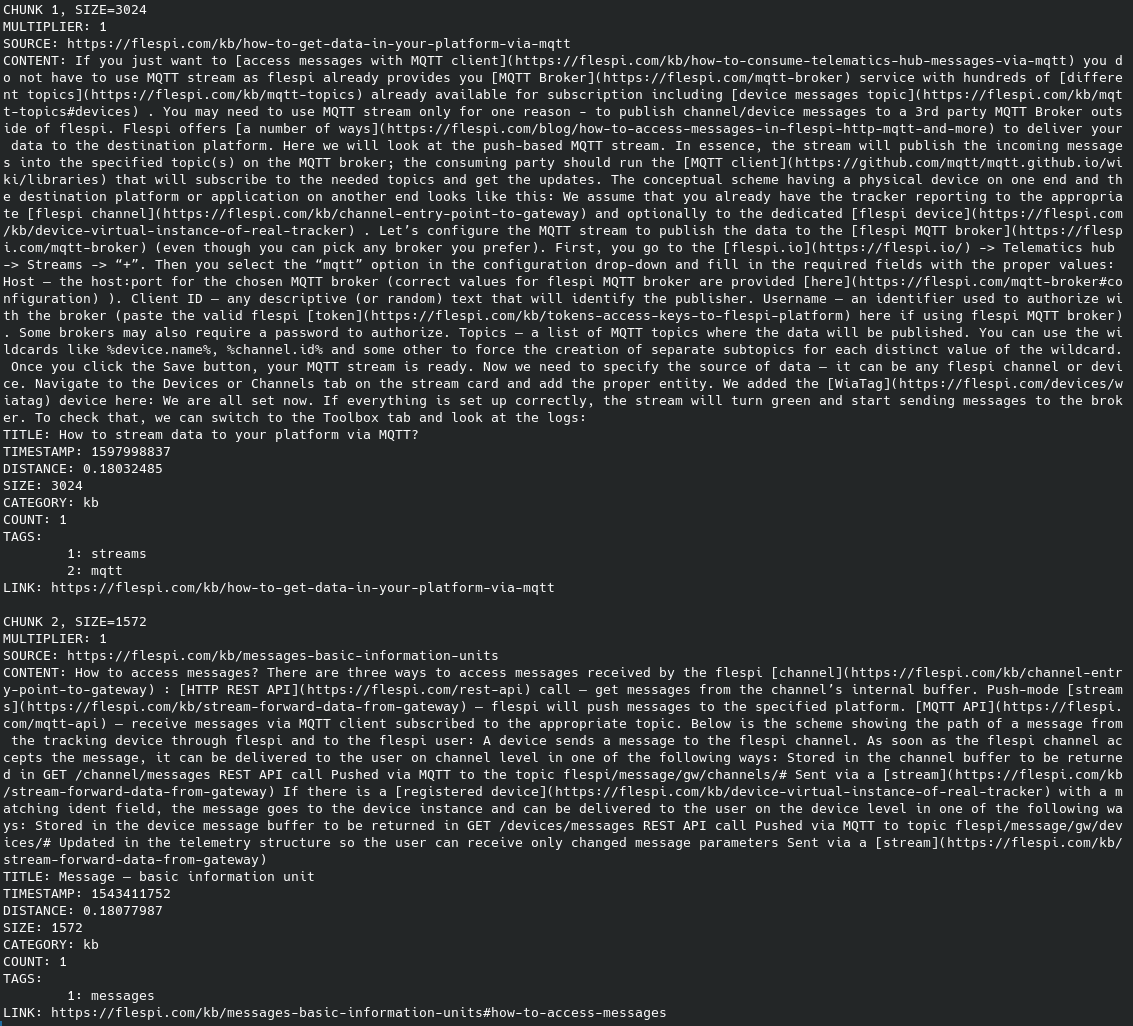
A distance of 0.18 is pretty good. Notably, the first two chunks precisely contain articles shedding light on the question context—how to consume device messages via MQTT. This exemplifies the synergy between the Weaviate vector storage and OpenAI vectorizer in finding semantically aligned text chunks—an approach highly recommended!
We perform eight calls to Weaviate, retrieving chunks from diverse sources related to four contexts. Each call returns up to 40 chunks of knowledge with a semantic distance of less than 0.25 from each context. These chunks are subsequently sorted based on category, distance, source, etc., and consolidated into a single chain of knowledge, comprising up to 200 text chunks and totaling up to 50,000 characters. This single knowledge chain is then supplied to LLM, enhancing its intelligence.
Knowledge links with a distance of less than 0.22 from various sources are also added to the message within the "AI Assistance" block. These links can be checked to discern the type of source supplied to AI in response to your queries:

Answer generation
Upon gathering a chain of chat messages and a set of related knowledge chunks, we initiate a chat completion API call to generate a response from LLM. The prompt comprises:
- Base prompt: seven lines of text conveying the AI's mission.
- Knowledge chunks annotated with links, guide LLM to craft replies based solely on that knowledge.
- Recent chat history between the user and the assistant.
- Generic flespi information—identical to the 16 lines of text provided for summary and context retrievals.
And that’s it. It typically takes LLM around 10 to 50 seconds and approximately $0.01 to post a comprehensive response to a chat. This is significantly more cost-effective and quicker compared to an experienced human consultant. And it’s available 24/7/365, being absolutely correct in 85% of answers.
Is it secure?
- In accordance with OpenAI's security policy, data submitted through the OpenAI API is not utilized for training OpenAI models or enhancing its service offerings. Moreover, OpenAI extends its services to European customers in compliance with the European GDPR law.
- Users retain control over whether their messages are directed to an AI assistant or solely reserved for human interaction.
- At a larger scale, it's possible to employ locally installed smaller LLM to wipe out various credentials from user messages before submitting them to a third-party cloud-based LLM.
What’s next?
The pace of generative AI development is currently exhilarating, it’s kind of a technological boom. While not all applications might sustain themselves in a year or five, those ignoring the usage of generative AI and bypassing experience might lose this battle in the future. We've tested this technology and fine-tuned it to suit our requirements. Despite diverting time from our primary focus on telematics, this investment has helped us save time by diminishing the need for extensive consulting services. The AI is now capable of consulting users on a broad spectrum of topics, ranging from device selection to crafting code snippets for specific flespi-related tasks.
Looking ahead, depending on the extent to which we further develop this technology, the generative AI could potentially:
- Integrate channel protocols based on manufacturers' specifications provided.
- Compose plugins in PVM.
- Suggest calculator configuration for tasks set in natural language.
- Configure various systems within the flespi account solving real-world tasks.
Although it won't replace human interaction in a chat or tackle the complex questions we handle daily, it will adeptly handle the routines, freeing up our time for more challenging tasks. At least, I hope so. ;)