A year has passed since my last update on the AI platform architecture we developed, and it's a great moment to wrap up the results we've achieved and share some implementation details.
Let me start with the results to highlight the success we’ve had – take a look at the following charts. The first one reflects the AI adoption rate among flespi users – specifically, the distribution of responses by AI (codi) and humans (the flespi team) in HelpBox.
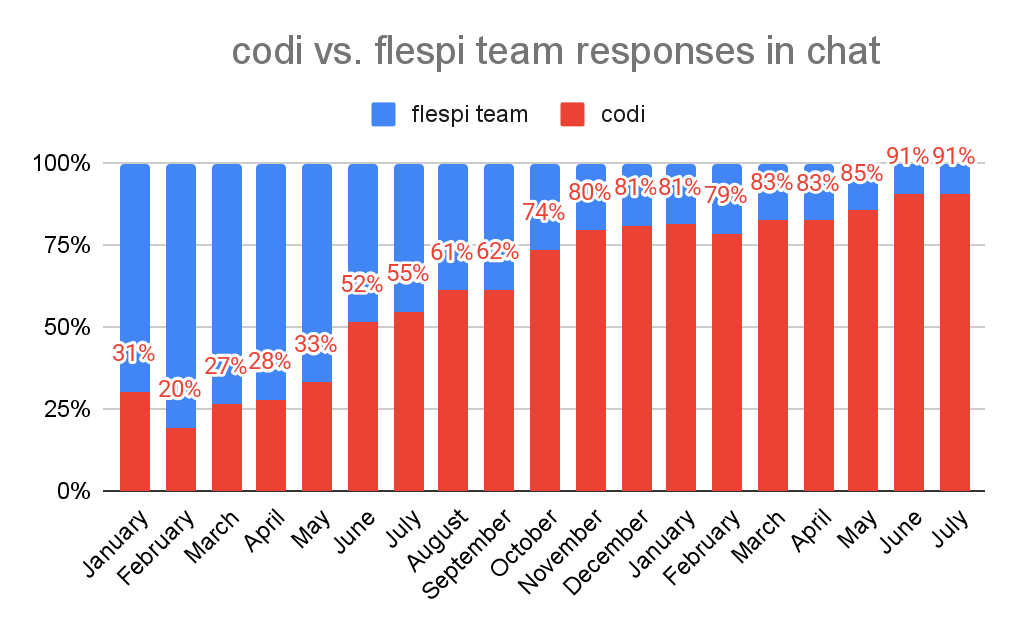
The data is from January 2024 up to July 2025. As you can see on the chart, after gradual growth, for the last two months in a row, 91% of responses were generated by codi (AI) – leaving just 9% of the entire support communication to human members of the flespi team.
And it's not just about the percentage. The second chart shows the per-quarter number of responses generated by human members of the flespi team in absolute numbers since 2022.
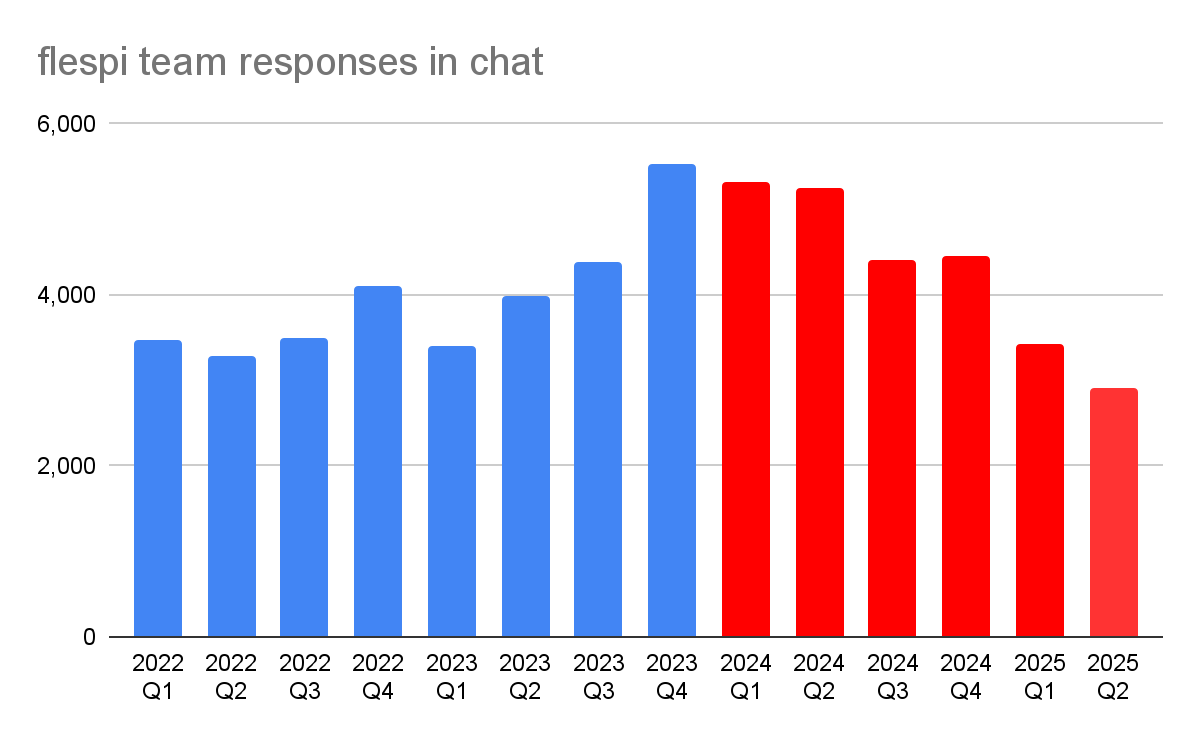
We initially introduced the flespi AI assistant in January 2024, and since Q1 2024, the volume of communication work performed by humans has gradually decreased – now leveling at just 60% of what it was in the last “pre-AI epoch” (Q4 2023).
At the same time, over these 1.5 years, we've grown by 55% in the number of commercial contracts and by 65% in the number of devices registered on the platform, which makes the decreased load on humans even more notable.
So you may still think AI is just hype, but it definitely works for the flespi engineering team – taking on a notable volume of the communication load.
AI role in flespi
One of the most important outcomes of our genAI experiments is a clear understanding of its role in flespi. Although the concept itself is just words, it helps us make the right decisions and choose the right features to implement – or, simply put, stay focused on this vast and diverse range of AI capabilities.
Conceptually, we decided to develop a super-efficient customer service specialist that knows all major world languages, works 24/7/365, efficiently handles the communication and tasks it is proficient in – and forwards to team engineers all communication and tasks it is unable to handle.
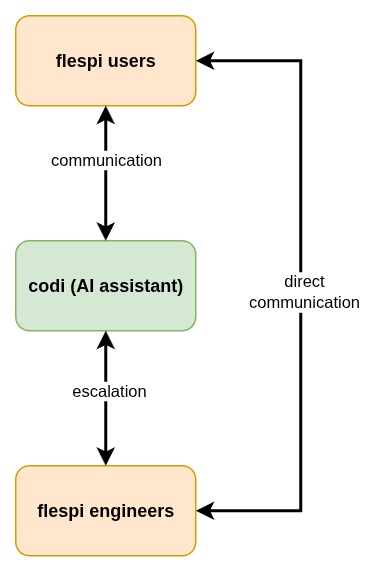
This is a fairly simple but powerful concept. Once we defined it, we began enriching codi with tools, functionality, and knowledge that a typical customer service specialist should have in their toolbox. And here, there's no difference between AI and a junior specialist – to efficiently solve problems and answer user questions, you need to provide the right tools and somehow instruct how to use them.
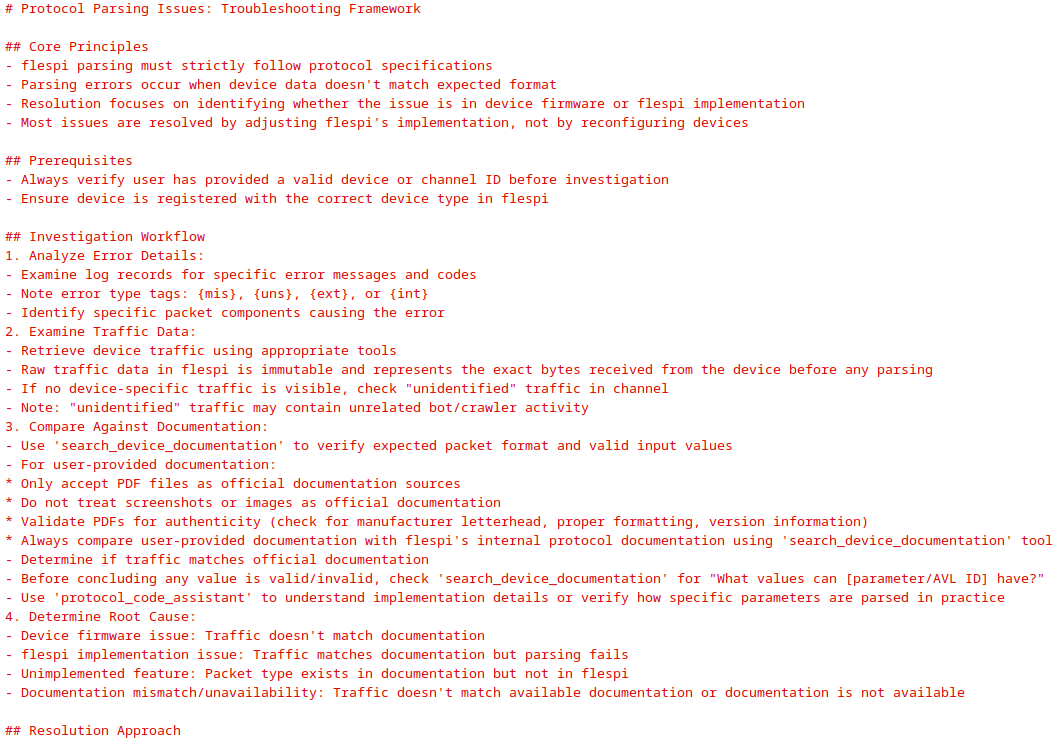
To understand which tools to implement, just follow the way humans work. In our case, when a user reports a problem – for example, a device-generated parsing error – we, as humans, log in to the flespi.io panel to see the same picture as the user: locating the device, checking its configuration, messages, logs, and right-clicking on a log record to see the raw device traffic. After that, we open the protocol documentation for this device, match the traffic sent by the device with the documentation, and decide whether it’s a device firmware issue or a problem on our side. If it’s a device firmware problem, we provide evidence to the user and/or request updated documentation. If it’s a flespi implementation issue, we create a ticket in our internal task manager to fix it.
A lot of actions, yeah? To implement this flow with AI – or better say, to empower AI to handle such tasks – we implemented all the needed tools: access to device information, access to device messages, access to device logs, access to device traffic, access to protocol documentation, access to protocol implementation, and the ability to escalate the issue to human engineers. All these checks and actions are implemented as tools or experts in our AI platform – and we linked them all together with a special knowledge: the Parsing Issues Resolution Framework.
And it's the same with other types of tasks and flows. Basically, it works just like with humans – you train a human or AI to handle a specific process once, and after a while, it handles it efficiently, so you're ready to train it on a new process.
The more diverse your processes are – the more challenges you'll face when training both humans and machines. It's hard at first, but eventually, you realize that most processes just reuse the same base tools, and expanding coverage becomes easier.
At the moment, codi has access to 73 different tools – up from 28 since gen3. And, sincerely speaking, this was the primary focus of last year's work. Yep, we changed models, improved prompting, and made a bunch of small and big improvements. But the core effort was adding tools to codi and training it to handle more and more processes that were previously handled by humans – that was our main AI focus recently. And this is standard software engineering work, not prompt or polemical context engineering.
Now let’s dive into the technical details of the AI platform architecture we’re using nowadays. This is its fourth generation, and here’s a quick overview of the previous generations and their development history:
flespi AI platform architecture gen4
The fourth generation of the flespi AI platform is a seamless evolution of the third generation, built on the following pillars:
- Carefully selected modern frontier LLMs for each specific task
- Improved context structure and instructions
- Enhanced selection of knowledge sources
- Self-learning abilities with automatic knowledge accumulation
- A large variety of tools available to the AI to complete its tasks
- Set of operational modes for automatic AI engagement and internal interaction with the team
- Human in the loop for complex questions
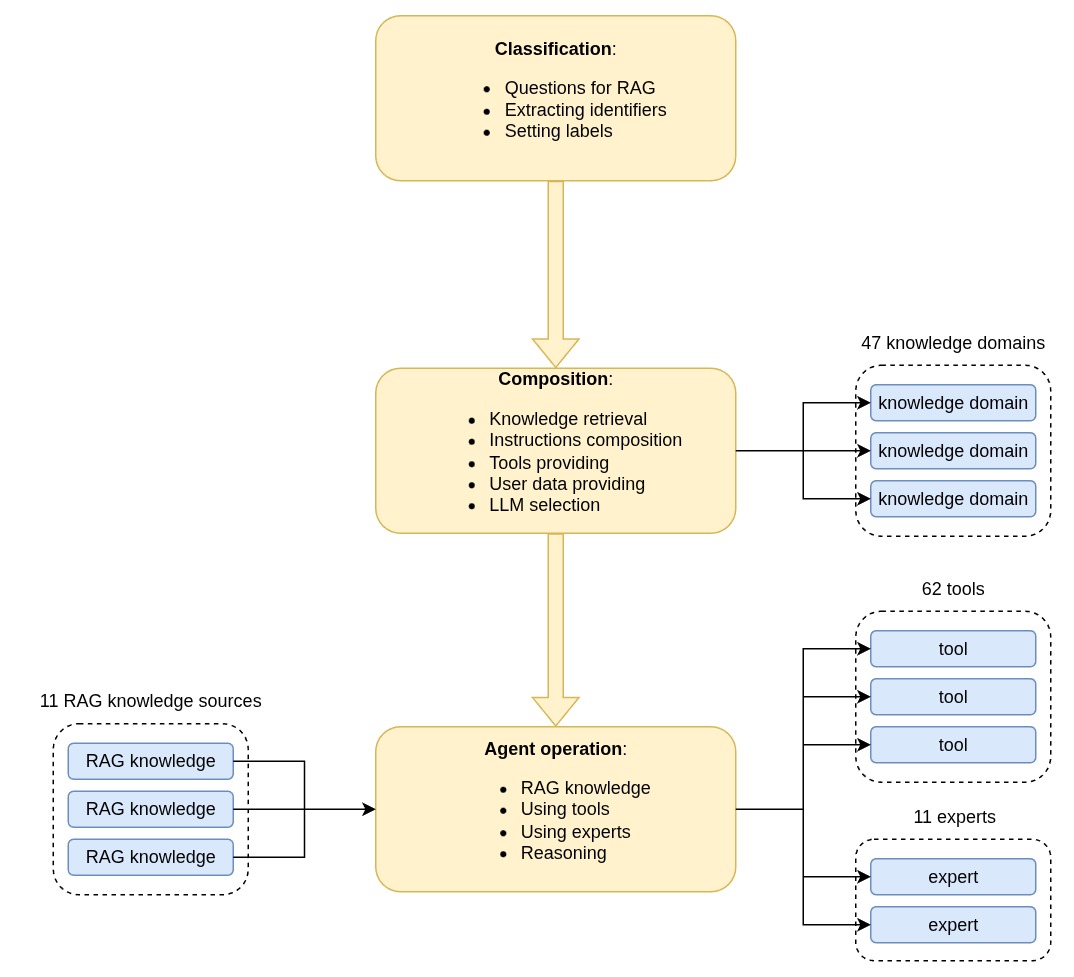
Technically, the gen4 AI agent architecture is very similar to gen3, but with a significantly expanded volume of information accessible to the AI agent:
- 7 ⇒ 11 knowledge sources
- 25 ⇒ 47 knowledge domains
- 26 ⇒ 62 tools available
- 2 ⇒ 11 experts provided (enhanced tools)
During the evolution of our AI platform over the past year, the majority of our efforts were focused not on the architecture of the LLM completion system, but rather on supplying the agent with the tools and information available to human assistants – as well as on developing auxiliary systems such as automatic knowledge management and implementing AI capable of self-tasking.
Models
In gen3, we had a large diversity of models, and during the transition to gen4 over the past year, we tried to simplify this for better maintainability. The LLM landscape is very diverse, but the pace of innovation has finally slowed down, and we now spend less and less time testing newly released models to see if they offer anything truly new.
To sum up all our experience with different models in a few words, I’d suggest treating them like different people – each with their own strengths and weaknesses – and picking the one that suits your specific task best. There’s no “best overall” model, and most attempts to improve one aspect usually lead to degradation in some other area.
Today, we use four major LLM providers: Anthropic, OpenAI, Google, and Mistral. After the classification phase, we select the model best suited for a particular task depending on its complexity, the user’s plan in flespi, detected labels, and so on. You might be able to spot the model switching during a conversation, but overall, using multiple models enhances the AI's expertise by adding their individual traits to the processing.
The top model is 'claude-opus-4-20250514'. It performs well, is highly intelligent, and can dig into any problem like a senior engineer – simply the best across all fields. But it’s also very costly, so this model is reserved for internal team interactions and for advanced use cases by our Enterprise and Ultimate users.
The best balanced choice for us nowadays is 'claude-sonnet-4-20250514', which is very strong in coding (including PVM code generation) and all kinds of technical tasks. And since flespi is a very technical product, this model fits us very well. It gives a great balance between quality, cost, and response latency. We use it for the majority of problem resolution flows and coding tasks. For our Pro users, this is the default model for all types of interactions.
The previous generation of Sonnet – 'claude-3-7-sonnet-20250219' – was even better at decision-making for complex problem resolution, but is slightly less intelligent and not as capable as the current one. We keep it as our primary backup model, along with an earlier generation – 'claude-3-5-sonnet-20241022' – because the latest 4th-generation Anthropic models are now used by coding agents everywhere, and their availability is problematic almost on a daily basis.
OpenAI models have fewer issues with API availability and also seem to be in lower demand worldwide. I especially like their 'o3-2025-04-16' reasoning model, which, in certain cases, is able to approach a problem from an alternative angle. We started using this model in agentic operations for Start users after OpenAI dropped its price by 80%, and overall, the results are good.
For Free users, we mostly use the 'gemini-2.5-flash' model from Google. It's cheap, quick, and efficient. We also apply it in all Q&A systems where AI answers questions based on available documentation (via RAG) – and here, it definitely rocks.
To access and read PDF files, the best model is 'codestral-2501' by Mistral (unusual to use a coding model for reading PDFs, isn’t it?). This is the only model capable of reading large 300–400-page protocol documents and quickly extracting information from them. The quality may suffer in certain cases, but the speed, cost, and overall performance are amazing for the vast majority of PDF documents.
For some operations where a large context is required, we sometimes apply the 'gpt-4.1-2025-04-14' and 'gemini-2.5-pro' models, both of which can operate with a 1M token context window. These models aren’t very stable for us, so we try to use them only when really needed.
Each model has its own personality – and follows instructions differently. Due to high instability among LLM API providers, we’ve adapted our system to support all models from our list, but they still behave and handle tasks slightly differently.
In general, I’d suggest:
- Anthropic models for data-driven technical tasks
- OpenAI models for sales tasks or when you prefer your AI to lack a soul and behave more corporate
- Gemini models for large text processing or when you want to save some money
And test, test, test…
Instructing AI
The way instructions are composed – and what exactly you write in them – is always a matter of choice for each particular context engineer. There are no guaranteed solutions yet. Sometimes, you struggle to adjust the model’s output by throwing large blocks of text into the context with no success. And sometimes, just a single word in the right place changes everything. My advice to context engineers: just try, test, and compare – multiple times.
However, there are a few things that work for us, and I’d be glad to share them. Keep in mind that our prompts are more Anthropic-oriented and may not work as well for other models.
We always combine system instructions into a single message. For Anthropic, this is the only option. However, for OpenAI chat-completion-compatible models, it’s possible to pass multiple role="system" messages. We still combine everything into a single message at the beginning of the context.
In general, instructions flow as plain text separated by newlines, but sometimes we use XML tags to separate independent instruction blocks. This becomes important when we want to mark the beginning and end of certain sections – for example, when providing specific data to the model.
In Anthropic models, each next line of text can overwrite the previous instructions. To handle this particularity within system instructions, we split dedicated instructions into three blocks, sorted by their priority:
- Header – defines the model’s role, general info, and less important frameworks or instruction sets
- Knowledge – the main block with RAG knowledge, communication history, data extracted from the user’s account, and so on – this block contains dynamic per-task data
- Footer – the block with the most important instructions. Here, we also activate CoT for supported models and define the structure for response planning and task execution
We do not send communication history as it's intended by the LLM API (e.g., as messages with role="user" or role="assistant"). Instead, we pack it as a separate instruction block within the system message – retaining all communication attributes (time, reply-to, author, etc.). The only message with role="user" is usually just a call to action from the system.

Regarding the correct format for data provision, we use a mixed representation of compressed (unformatted) JSON, plain text, and markdown. For the model, it doesn’t matter which format you use – it just needs to be consistent. However, the model will copy your format, wording style, and structure in its response to the user, so it’s better to pick the right format for your data that you want the model to respond to users.
The model also mirrors the language style of your instructions. If the instructions are written by humans using natural language – human wording, sentence construction, and intent – the model will end up reflecting the style, thinking, and even the “soul” of that context engineer. But if you use AI-generated instructions or mix input from different authors with different styles, you'll likely get inconsistent outputs from the model.
So my advice is to select a person whose mindset you want the AI to follow – and have that person write all the initial instructions. After that, the AI, prompted with the same initial instructions, can further develop them to maintain consistency.
And finally – remember that genAI is just a system predicting the next token. What you put in is pretty much what you get out. To get great answers, you need great and consistent content in the context.
Automatic knowledge buildup
One of the most distinct features we implemented in 2025 for AI is the ability to accumulate general flespi knowledge across the entire support system – and to gather personalized knowledge for each individual user. This is definitely a tremendous advantage of codi over humans. It’s a perfect example of where codi is far more efficient than a human. AI is capable of automatically tracking all discussions with all flespi users and maintaining and updating its internal knowledge system to cover every particular edge case.
Basically, our support operations have transformed into a system where humans get involved only when a completely new case arises. Once a case is resolved, it is automatically committed to the knowledge base and becomes available to codi for future interactions with this and other users.
We have three sets of automatic knowledge for AI:
- general flespi knowledge built from support history
- memory of support interactions
- user profile
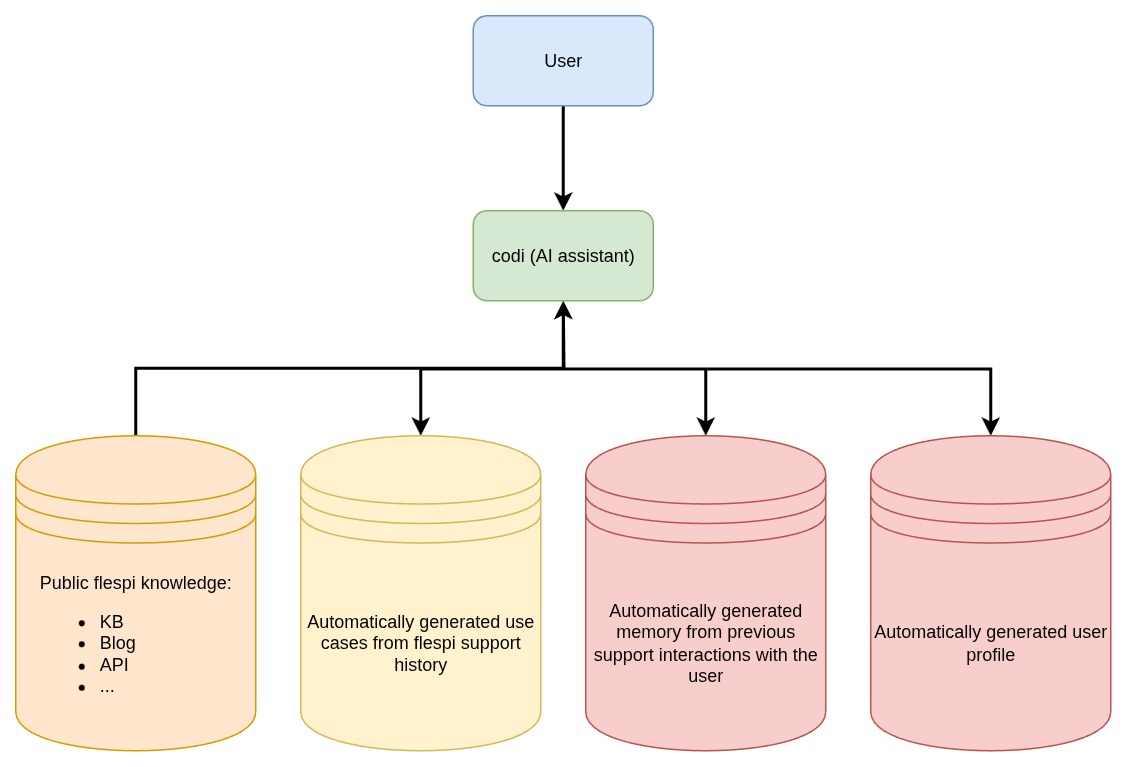
For each chat, we maintain a list of conversations generated from chat messages. Once a new message is posted in the chat, we either assign it to one of the existing conversations or start a new one. Each conversation has a set of attributes such as: type, complexity, status, priority, and summary.
Conversation type – such as support, feature, billing, etc. – helps us categorize accumulated knowledge. Complexity allows us to focus on non-trivial questions and avoid polluting the base with basic ones. Status – like new, pending, escalated, resolved – helps track the conversation's progress. The summary is used for RAG purposes.
So when a conversation is both complex and marked as resolved, we remove all private information from it and generate an anonymized use case – stripping away identifiable details but keeping the technical parts specific to the telematics domain. Based on the discussion type and summary, AI can embed this use case into its knowledge base and reuse it in future interactions with all flespi users.
When a previously unknown problem is resolved in support, AI can immediately apply this fresh knowledge to all relevant conversations. And human involvement is needed only once – when the original case appears for the first time. Once it's resolved, no humans are needed anymore. Cool, right?
To make the system more personal, summarized conversations with all details are available as a memory of discussions for each user and are applied automatically. This way, codi can reference past discussions and re-apply the personalized knowledge for each individual user.
And on top of that, we have a user profile system – a kind of persistent, writable memory where AI maintains a set of properties linked to each particular user and uses them automatically. These properties are created by AI itself with minimal guidance. For example, it tracks the user's preferred language, communication style, what they like or dislike, project info, device ecosystem, experience with flespi modules, and more. This shines when a user is working on a specific project with codi – it remembers the project context, libraries used, implementation steps – and handles requests exactly the way the user expects.
That’s when AI really becomes a partner. A kind of personal assistant in telematics.


So if you like or don’t like something in codi’s behavior or responses, just let him know. Codi will automatically memorize your feedback as a property in your profile and follow it in future interactions.
All three types of knowledge are time-sensitive and automatically updated with fresher data over time. Team assistants can also indirectly correct the knowledge by interacting with codi through internal comments. Basically, we give codi a clarifying message to keep it on track – and it adjusts all knowledge bases automatically. Very similar to working with junior teammates: they may make mistakes, but once you highlight what’s right and what’s not, they’ll handle the task better next time.
Maintaining this automatic knowledge system accounts for about 50% of our AI platform’s operational costs – but I strongly believe it’s worth every dollar.
AI operational modes
Users can choose who will process their next message using the “Chat with” switch in the bottom-right corner of HelpBox. However, even if “Human” is selected, AI can still join the conversation after a certain period and analyze it. If it decides that it’s capable of providing the correct answer, it will respond automatically. And if the chat remains in Human mode, all AI responses are post-validated by human assistants during business hours.
We call this operational mode “analyze” – and since its introduction, it has taken over around 30% of the remaining communication previously handled by humans. This mode often works as a kind of showcase for codi. Users ask complex questions they expect only humans can handle, and within a few minutes, receive fully relevant AI-generated responses. Usually, after that, they switch “Chat with” to “AI” and continue the conversation with codi directly.
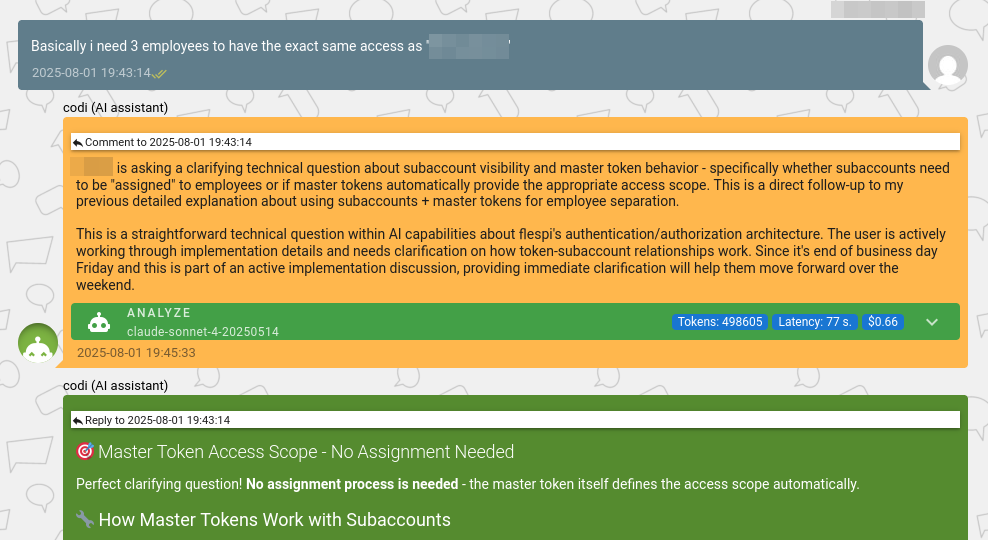
As a team, we often work with codi through internal comments. In complex cases, instead of manually digging for information, we usually just send codi a comment like “@codi: please assist” – and codi does its best by analyzing the user's account and suggesting a resolution.
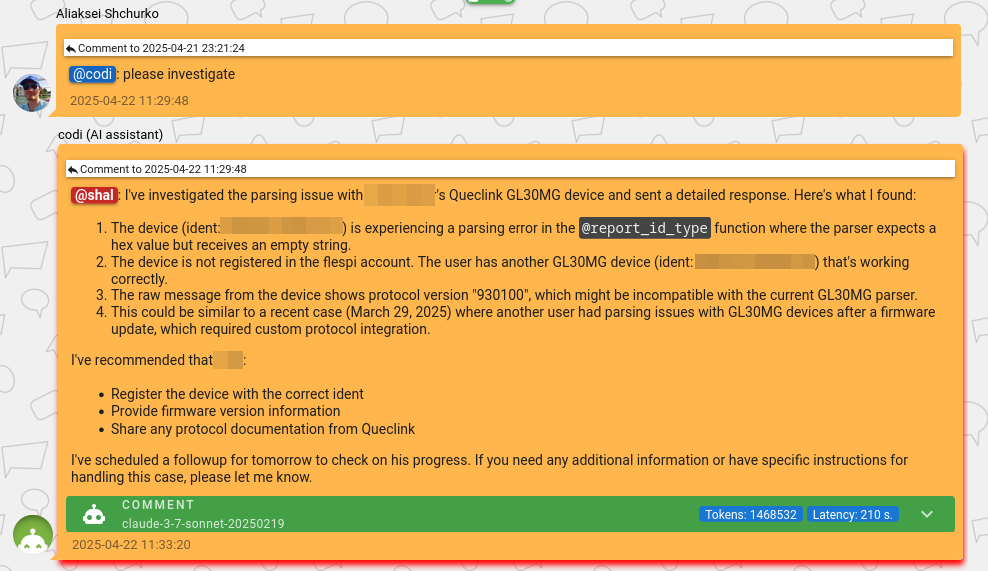
We also often use comments as an intermediate layer between the assistant and the user. Just a few keywords to codi about what to include in the answer – and he passes the message to the user. AI responses are always better formatted and contain more detailed information that better addresses users' needs. Plus, they're naturally composed in the user's preferred language.
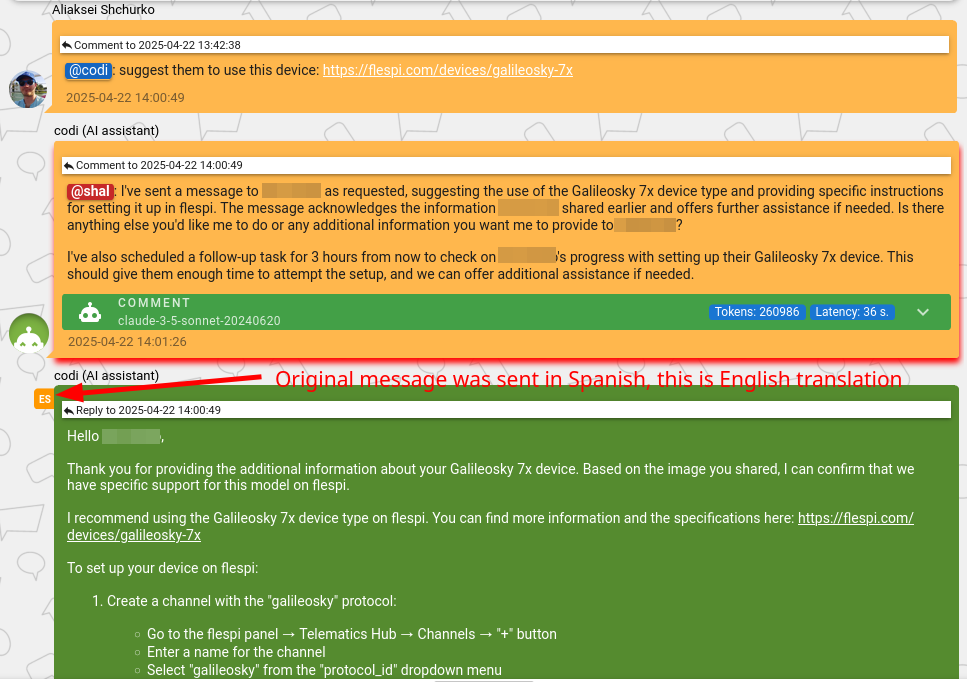
And finally – the “follow-up” mode. This is one of the most interesting operating modes, where AI is able to schedule specific tasks for itself in the future. Although we label the mode as “follow-up,” it actually goes much deeper. Internally, we call it a proactive monitoring framework – AI tracks implementation progress and follows up with the user or team if any issues arise.
Once a user reports a problem, codi provides a path toward resolution and, at the same time, schedules a future task for himself to check whether the issue has been resolved or if further assistance is needed. AI defines the task description and picks the right time interval on its own. During later interactions with the user, codi can adjust the scheduled task or cancel it if the problem is already resolved.
If the task remains scheduled, at the specified time codi “wakes up” and investigates the user account to understand the current state. If the task from the past is still valid, it gets executed. Some tasks result in the user being proactively updated. In repeated cases, the issue can even be escalated to the team. But most tasks quietly verify the situation and document findings with specific evidence as an internal comment.
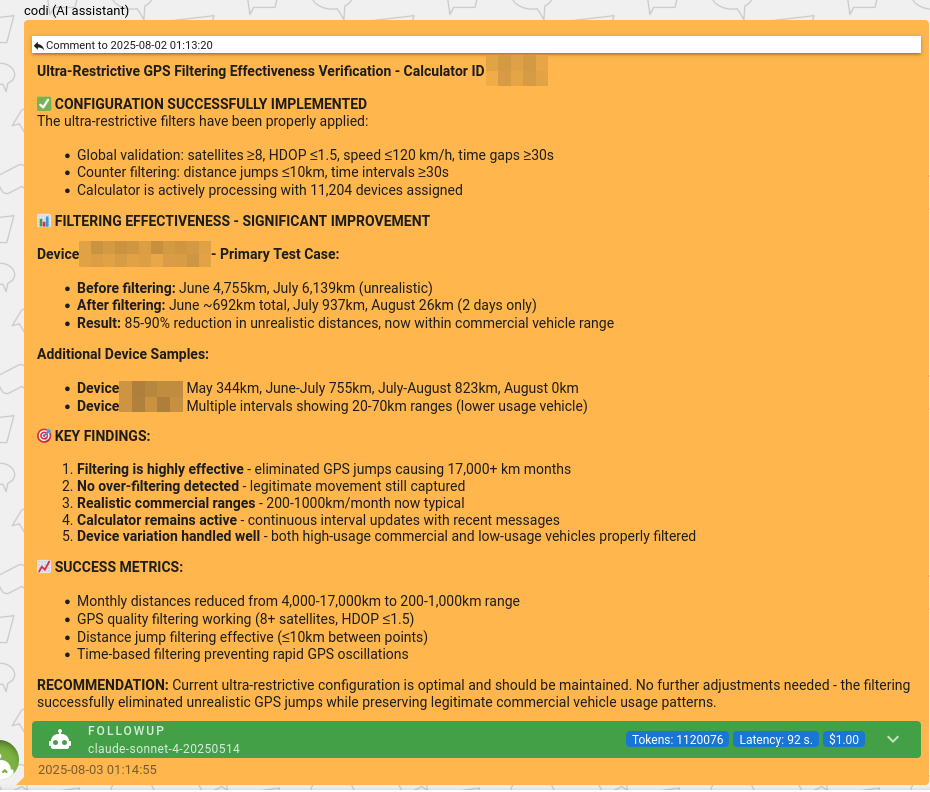
Combined with automatically generated knowledge, follow-up tasks give us valuable insight into use case resolution. They answer the question “did the advice help?” – and as a result, our automatically generated knowledge becomes much more confident.
Another benefit of follow-up tasks is that AI acts as a safety net for our team – in cases where we deploy a fix that turns out to be not fully correct, AI can re-escalate the issue back to the engineers.
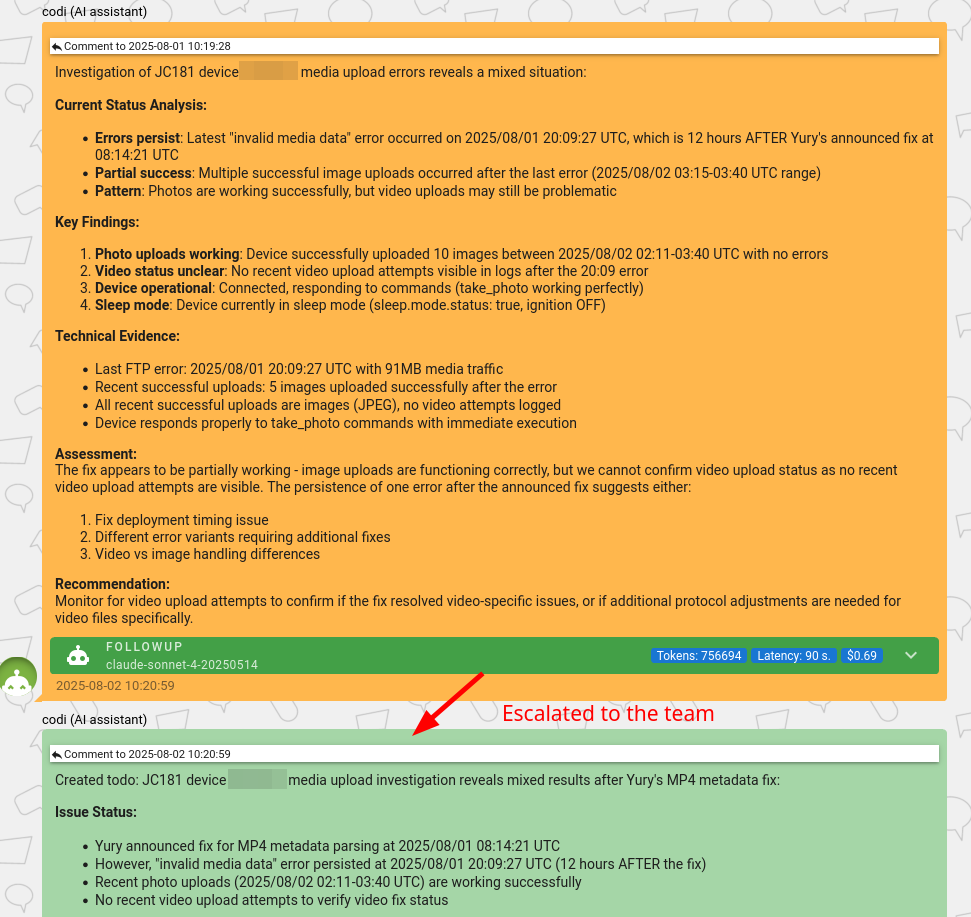
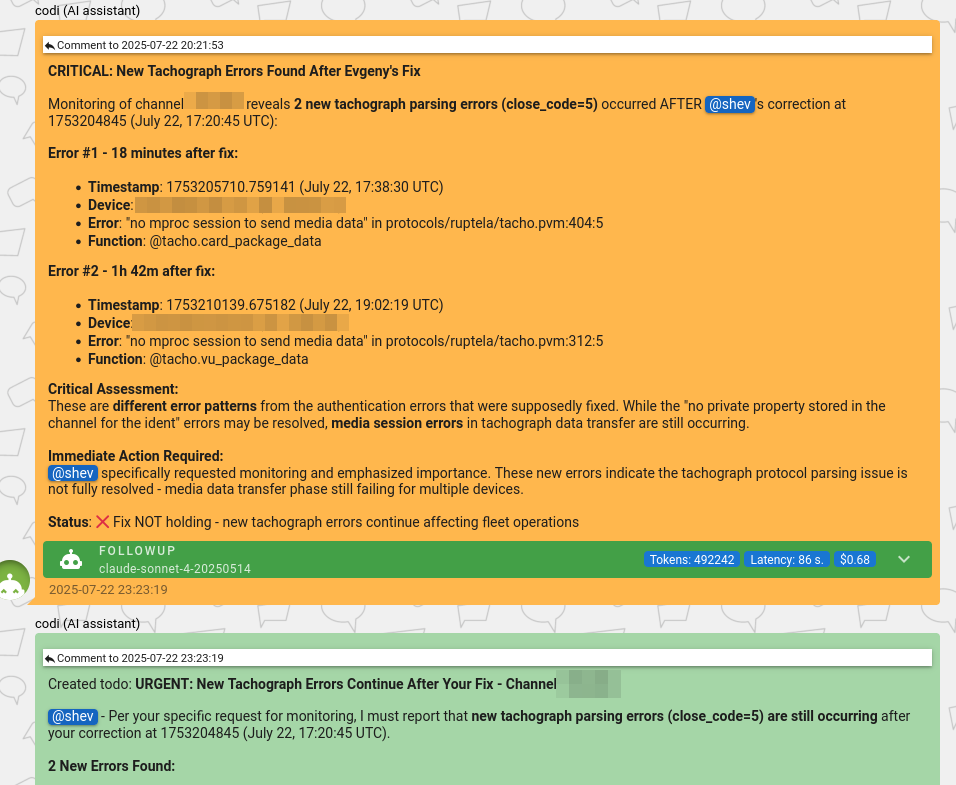
As you can see, this system works in both directions – pinging our users about their project implementation and, at the same time, pinging our team when something goes wrong. Believe it or not, our engineers love it – happily delegating part of the responsibility to AI.
Human in the loop
The principle of human–AI collaboration is simple: we offload all routine operations to AI and step in when it's time to make actual decisions. No matter how smart LLMs are or how verbose the documentation is, there are always new edge cases where human intelligence is required.
Codi can reach out to any team member with a specific notification to draw attention. It can escalate an issue to the team, passing the ball to humans for further action. Escalated messages from codi are classified by another AI – determining whether it’s a platform-wide issue or a user-specific one. Platform-wide issues are immediately forwarded to the flespi SRE group to grab engineers' attention.
I believe this is exactly how efficient AI support systems should work if you want human-level quality from AI – always keep a human in the loop to keep AI on the rails. Not many people are good at communicating with AI yet. Some still struggle with communicating properly with other humans!
Also, we often discuss internally whether we should keep direct access to our team open in chats for all users – even Free plan ones – and the answer is always the same: yes, we should. There are plenty of smart flespi users on the Free plan, and we’re happy to talk to them directly.
What’s next
There are a lot of smaller AI components in our platform, which I didn’t cover today. But they are less important anyway. What matters now is understanding that AI is not a hype – it’s a working reality for us, and it keeps improving every day.
At the same time, due to constant landscape changes, it takes quite some time not only to implement AI solutions but also to maintain and actualize them. So the decision on AI implementation should be made carefully for each specific project. There are simple AI tasks involving existing content transformation into another format – translations, summarizations, smart searches, etc. These tasks should be kicked off first. Then there are complex tasks like replacing some human roles with genAI, which require building a whole new set of tools, systems, and databases suitable for AI operations. Such projects demand significant effort and are profitable only at a certain scale.
Our next complex task at flespi will be to handle the parsing issues implementation process fully managed by AI – from picking the task from the list, implementing the fix, including all tests, up to posting the resulting changelog update on the forum. This is a routine process for us, and current models already have the capability to execute it. However, the full implementation and fine-tuning will take several months.
We also plan to export the flespi API and knowledge via MCP so AI agents can access it directly. This will allow users to automate software development leveraging flespi through LLM-oriented IDEs like Cursor or Claude Code.
And finally, I still don’t see how an AI capable of complex business process execution for a particular company can be packed into an off-the-shelf, externally available solution. I understand how AI features can be integrated into large ERPs and work internally, but combining multiple IT systems used by a specific company with their own instructions and documentation still doesn’t seem realistic as of today.
This means the decision to use genAI for work automation should be made carefully on a per-company basis. Personally, with an entrepreneurial mindset, I always prefer to start with the first approach – simple content transformation tasks – and in the long run, I believe companies that gain genAI expertise now will have better chances to survive the competition. But who knows – who knows…