In the latest June 2024 Changelog, I shared the results we achieved with codi, our AI assistant. Here are the same statistics expressed as percentages, along with preliminary data for July (not yet final):
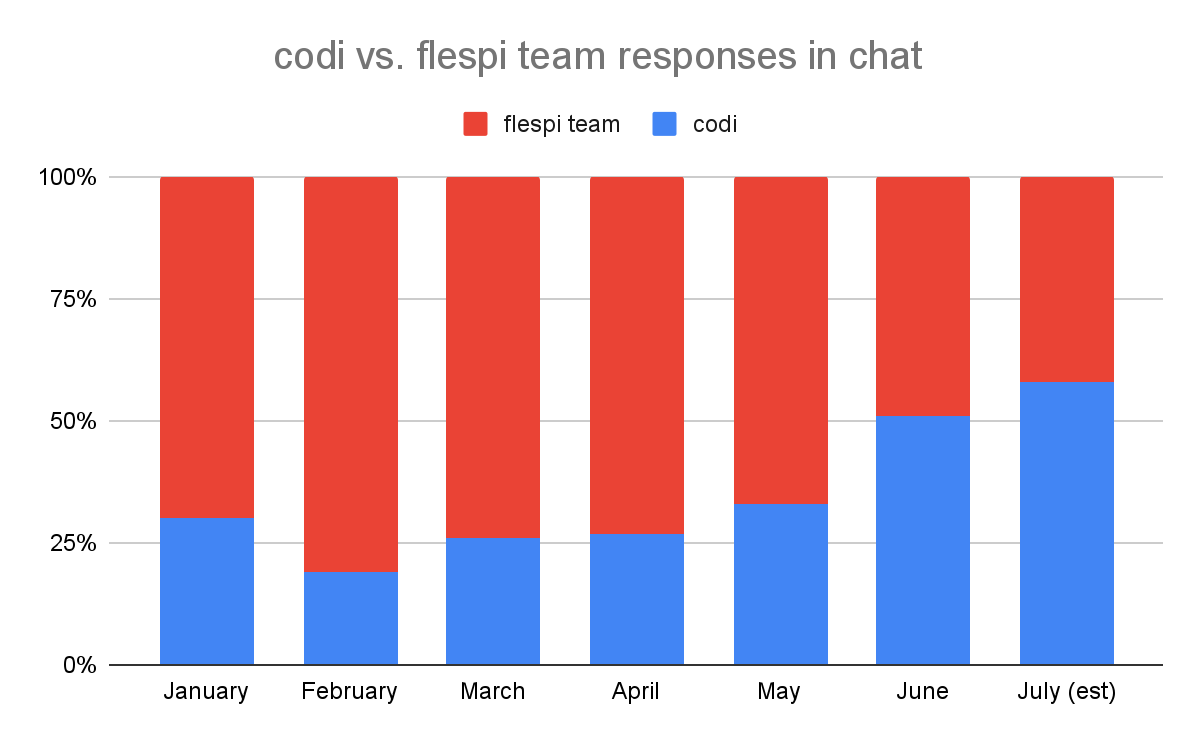
As you can see, it organically grew from month to month and then boomed in June. Once this happened, and we detected a preference change among our users to chat with codi rather than with humans, we enabled its engagement in semi-automatic mode. However, it's important to note that chat AI usage surged before we enabled semi-automatic codi engagement.
It was the combined result of focused attention on our AI platform, the knowledge we constantly adopted for AI, and the third secret ingredient: a set of LLM models we use for chat completion.
In this article, I will share the best practices and know-how we’ve developed from spending thousands of hours on AI over the last 9 months. This experience is quite unique because our entire AI platform has been crafted in-house from the ground up and it doesn't rely on external modules except for two of them: the LLM text generation service and vector storage for knowledge retrieval.
Here’s what we’ll cover:
AI platform architecture
Let's make a little dive into the 9-month history of harsh riding the AI — from zero to full-featured platform.
First generation
I became acquainted with AI in October 2023, and by the end of December 2023, we released the very first generation of our AI platform.
In short, it was a highly efficient live documentation system. Its primary goal was to generate answers based on the knowledge in flespi documentation, saving our users time from searching for and reading our Knowledge Base articles.
From a technical point of view, it was a two-stage architecture. In the first stage, it generated a chat communication summary, which was then used to retrieve chunks of knowledge from the vector database. These chunks were then embedded into the LLM prompt to supply the model with the most recent knowledge. The model was instructed to formulate the answer using reasoning based purely on the embedded knowledge. You can read more technical details here.
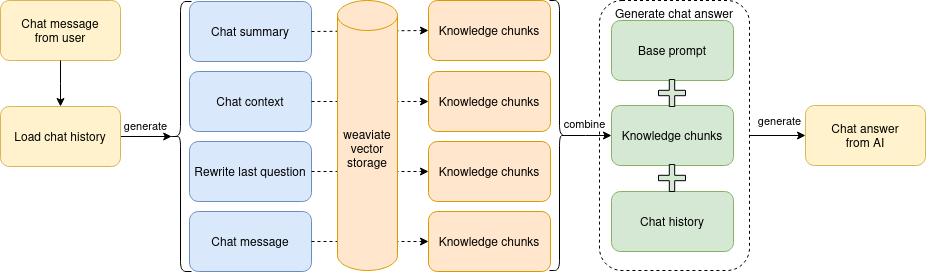
Such architecture is called RAG (Retrieval-Augmented Generation), and it worked exceptionally well. However, the limitation was the context window size and the amount of instructions and data we could supply to the model. Essentially, if we wanted more (and we did!), we had to change something to accommodate divergent and unrelated tasks.
Second generation
Our next step, the second generation of the AI platform, was released at the end of February. We completely revamped the platform architecture and split the answer generation functionality into different independent modules: a module that handled the communication part and several modules focused on serving narrow knowledge domains. We called the communication module the "agent", while the narrow knowledge domain modules were called "experts".
The agent's primary mission was to communicate with the user in their language, query specialized experts in English with questions, and combine their responses into a single answer for the user. The agent was provided with minimal access to user data and had very limited knowledge about flespi — just enough to understand which expert it needed to forward the question to. It didn’t use any RAG either; it simply orchestrated the communication with the user by querying experts and combining the information received from them into the final response.
Experts, on the other hand, were designed solely to answer questions within specific knowledge domains and had no access to the communication context in the chat. Initially, we started with support and API experts.
The support expert was essentially an instance of our first-generation AI platform. It no longer needed the chat context summarization layer and directly passed the question from the agent to the vector database to retrieve related knowledge chunks for RAG. Over time, we equipped it with additional tools it could call on demand, such as a PVM code generator, which we also tested as a dedicated expert at one point, and a flespi expressions generation tool, which we considered providing to the communication agent as a dedicated expert.
The API expert was specifically instructed to correctly answer REST API and development-related questions. Its knowledge was primarily based on the flespi REST API documentation, and we equipped it with a special tool to provide the actual API call JSON schema when needed.
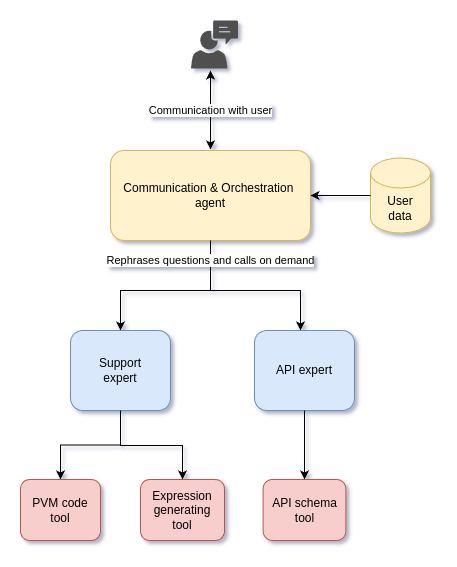
The architecture looked good on paper, but in real-life scenarios, several drawbacks became apparent:
Inability of the communication agent to correctly and stably identify which expert to address questions to. Some borderline questions, like programming on PVM or MQTT topics, were addressed to one or another expert during the chat session with the user, resulting in a not very straightforward and confusing line of answers.
Sometimes the communication agent answered questions directly without querying experts first. I believe this could be fixed with correct prompt instructions, but in the alternative case, we were losing the whole idea of this communication with an agent in the middle. And answers without expert assistance were immediately noticeable for their poor quality based on very generic knowledge. You could notice such answers when LLM uses words like "typically" — it just assumed something.
Response performance slowed down. LLM received the question, generated its own question to the expert, waited until the expert provided it, and then copied the expert's response. Almost twice as many tokens were generated in that scheme!
Still, experts lacked knowledge of real user data and were only able to answer theoretical questions.
The agent didn’t understand the value of the user data it was provided and could not correctly identify which pieces of that data to include in its questions to experts.
After initial testing followed by multiple attempts to tune this architecture, it became clear that an agent that communicates directly with the user must have RAG in order to behave correctly.
Third generation
As soon as we understood these problems, we started to work on the next generation of our AI platform, which we were able to release by the end of March — in less than one month. It combines all the best from the two previous generations, is powerful, easily expandable, and as of today, it has no known problems or disadvantages.
The platform consists of 3 layers:
Classification layer: It uses LLM to perform chat discussion classification, extracts various identifiers (e.g., device ID or ident), generates questions for RAG, and applies various labels to the discussion, such as devices, geofences, webhooks, billing, PVM, etc.
Composition layer: Based on the labels and identifiers extracted by the classification layer, it dynamically determines which LLM model to use for answer generation, selects knowledge sources for RAG, equips LLM with the necessary tools, embeds special instructions and user data from the account. For example, it includes invoice data for billing purposes, account counters when the user mentions account limitations; for each identified device its properties are provisioned along with the latest logs, messages, and so on.
Answer completion layer: Using the LLM model chosen by the composition layer, along with embedded tools and RAG knowledge, it generates the final answers.
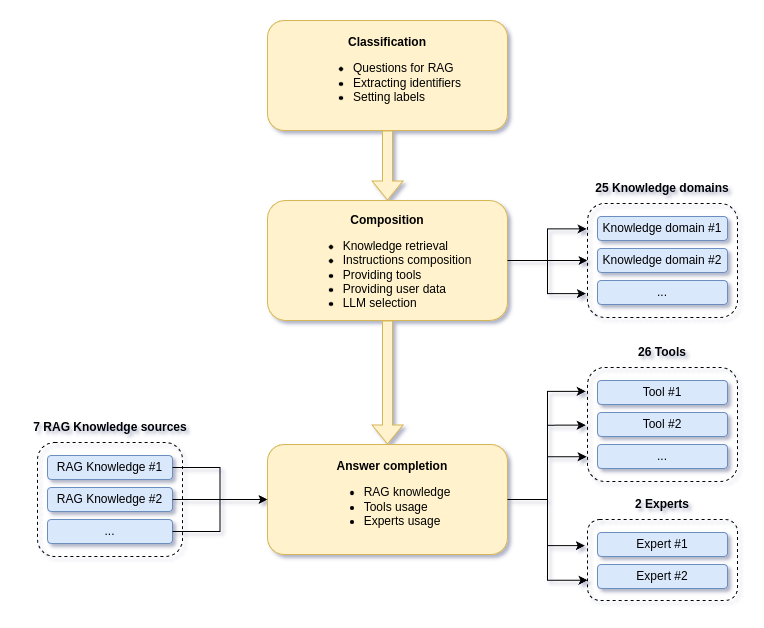
Currently, we have 38 different labels defined for the classifier, 25 knowledge domains that the composer sequentially tries, 7 different RAG knowledge sources, a redundant choice of 2 LLM providers with 7 different LLM models available for answer generation, and 26 tools, with 2 of them used as experts — for example, involving another LLM and our own RAG system during question answering.
The time and cost for each answer vary from 10 seconds and less than a few cents up to 5 minutes and $5 per answer in cases where LLM attempts to solve difficult problems and questions — for instance, conducting a deep investigation of issues with devices, including analyzing their telemetry, messages, logs, properties, configurations, and querying device manuals for additional knowledge.
When a human supporter tries to resolve a similar type of question, it can take from a few minutes to a few hours. Therefore, the costs are comparable, and AI is even cheaper. To acknowledge human capabilities, it's worth noting that in 20-30% of highly complex cases, codi sends a notification to our team requesting human assistance because it's unable to resolve the issue for some reason.
Below is a screenshot from our internal TeamBox system showing how codi sent a comment to our team when it was unable to diagnose the issue. This particular case took 2 minutes for codi to respond to the user:
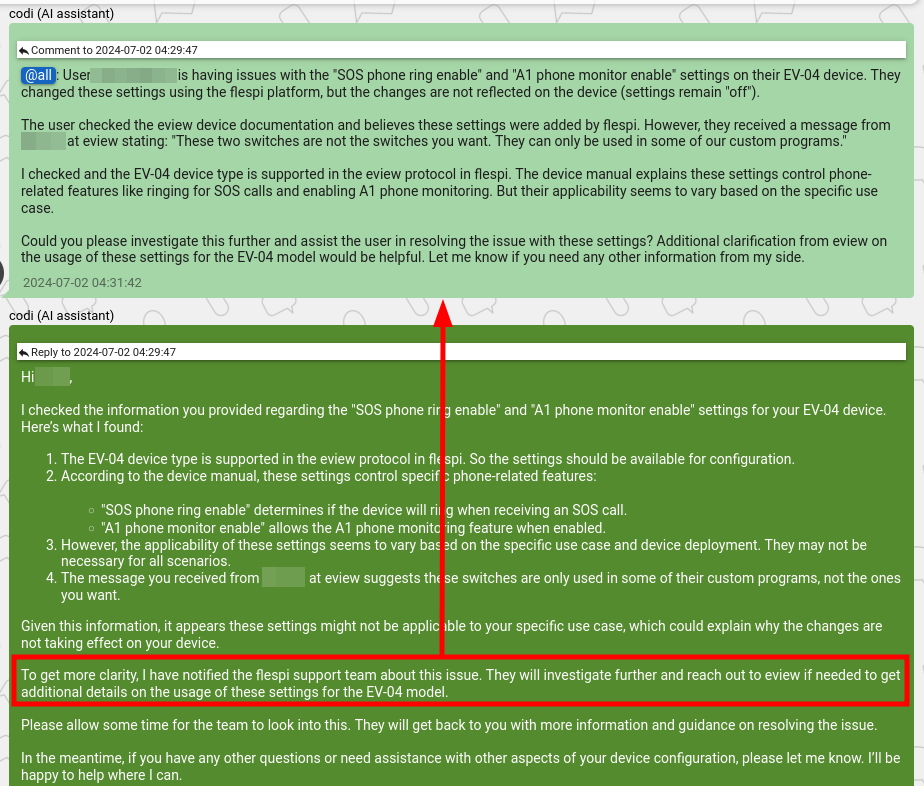
The main benefit of using classification and labeling in discussions is the limitless potential to expand codi with tools, knowledge, and instructions. We activate them for the answer generation layer on demand and only when they are truly needed, thus allowing LLM to focus on the real problem and saving tokens in the prompt for embedding more data and knowledge.
We also have two experts available as tools which codi can call upon to retrieve additional information in the platform:
flespi documentation: Provides answers to flespi-related questions. Codi uses this expert when the information in RAG is insufficient or detects something new during its investigation.
Device manuals: Answers questions about protocols and devices using official manuals from device manufacturers. Codi uses this expert to understand how devices work or during investigations into parsing errors.
Currently, these experts suffice for our needs. If we require knowledge from domains not directly related to flespi in the future, we can provision them to codi as specialized experts.
It's also worth mentioning the platform's vision capabilities. When a user or assistant attaches an image to the chat, we send it to LLM to generate a description of the image with all valuable identifiers extracted. Later, depending on the capabilities of the LLM used, when generating answers or performing classification, we either provide images to activate the additional vision layer or use just their text version.
LLM models we are using
The LLM (Large Language Model) defines the intelligence level of our AI assistant. There are many models from various providers, and almost every month a new model pops up on the market. The trick is that there is no single model suitable for all cases, and each model comes with its own set of advantages and disadvantages.
Smart models pose two problems — they are slow and costly. When a user asks a simple question, it's better to answer it quickly, saving their time and our money. On the other hand, dummy models, being cheap and quick, often fail to solve the issue or provide inadequate suggestions, creating difficulties for both users and us. Essentially, we constantly balance between a smart, slow, expensive model and a dummy, quick, and cheap one. We achieve this balance by carefully labeling communication at the classification stage.
Classification is arguably the most critical layer in our processing pipeline. If classification is done wrong and some labels or identifiers are not detected, we will definitely fail on the next layers. Therefore, we need the smartest model for the classification phase, capable of understanding all nuances in communication. We have found such model in 'claude-3-opus-20240229', which can accurately label communications and generate RAG questions that yield optimal results by selecting the most relevant knowledge chunks for the communication context. As a backup for classification tasks, we utilize the 'gpt-4o-2024-05-13' model.
Labeling at the classification stage greatly aids us in making informed decisions. For instance, labels such as 'resolved', 'feedback', and 'greetings' are applied to straightforward discussions. When these labels are detected, we activate the 'claude-3-haiku-20240307' model, which excels in handling such cases. To ensure effectiveness, we also limit the amount of knowledge in the RAG to prevent the model from over-explaining when it repeats the answer.
Conversely, labels like 'problem' or 'parsing_error' are assigned when users encounter issues or parsing errors. In such instances, we require comprehensive investigation and rely on the 'claude-3-opus-20240229' as the most advanced model and increase the volume of provided knowledge in the RAG.
For cases involving webhooks, calculators, or PVM code, we activate the 'claude-3-5-sonnet-20240620' model, renowned for its excellence in generating code and configuration-related content.
When no specific model is selected, we default to answering with 'claude-3-5-sonnet-20240620', with 'gpt-4-1106-preview' held in reserve. These two models strike the best balance between performance and intelligence for our needs.
Experts providing assistance for flespi documentation or device manuals use 'claude-3-5-sonnet-20240620' backed by 'gpt-4o-2024-05-13'.
For vision tasks that extract textual descriptions from attached images, our favorite model is 'gpt-4-turbo-2024-04-09', which consistently performs better at capturing important identifiers compared to other models we've tested.
For PVM code generation, we rely on 'gpt-4o-2024-05-13'. Anthropic models have failed approximately 25% of our PVM code generation tests, likely due to original prompt instructions tailored specifically for OpenAI. We also experimented with the open-source DeepSeek Coder V2 model under the same instructions, but it failed approximately 50% of our tests. Nevertheless, it remains an option.
Our use of various LLMs for different cases highlights the benefit of diversity, as each model behaves uniquely. Being LLM-agnostic allows us to select the best model for each specific case.
And because of this diversity, I believe there’s one major pitfall that all modern LLM-based AI startups will face. The instructions used in your prompts are usually fine-tuned for a specific model. While they may work with other models from the same provider, the results are likely to vary, necessitating a complete reconstruction of prompts if switching to a different LLM.
Furthermore, due to intense market competition, major companies release new models several times a year. With each release, startups must decide whether to adapt their prompts for the new model or continue using the older one. It’s not an easy choice, believe me. To maintain competitiveness, all GenAI-based startups should invest substantial time and resources into prompt refactoring, which is both time-consuming and costly. However, I remain optimistic.
To mitigate these challenges on our platform, we have implemented the option to compile in the prompt model or provider-specific instructions. For instance, with Anthropic models, we inject the Chain-of-Thought instruction, which immediately shifts model intelligence. Below is the raw output of the 'claude-3-opus-20240229' model resolving parsing errors in the device dataflow. You can see how it actually 'thinks', what it does during problem-solving, and its responses. Notably, various tools activated during the thinking and answering process are hidden from the output.
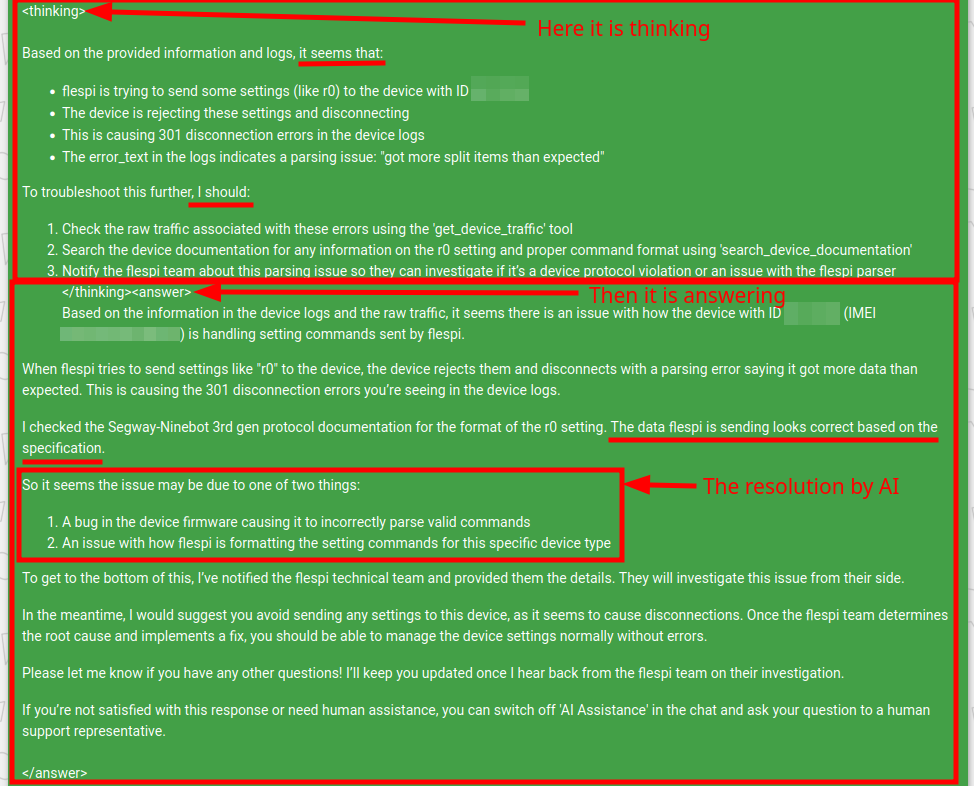
The full response took 85 seconds, involving 3 tools: retrieving device traffic, querying device documentation for packet parsing specifications, and sending a notification to the flespi team for further processing.
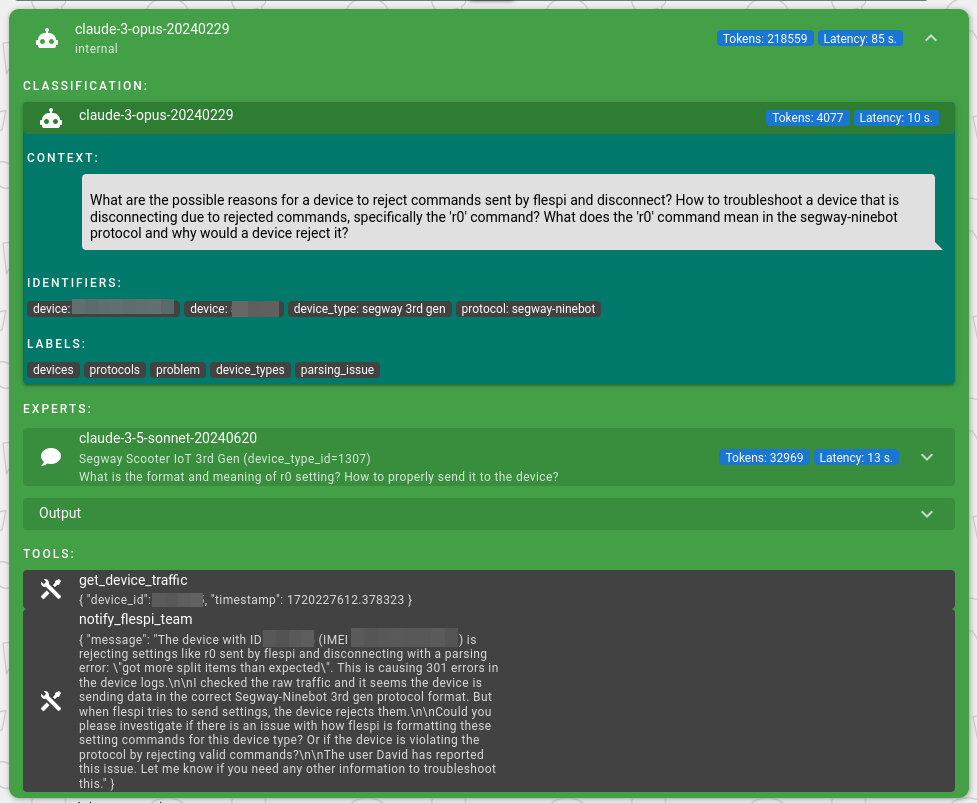
Exciting, isn’t it? :)
Knowledge administration
Knowledge, or in other words, content, is one of the most valuable aspects of a successful AI-based assistant. We store all our content in a local instance of the Weaviate vector database using different class instances for various knowledge domains. Within each knowledge domain, we also utilize categories and tags to organize specific content segments.
Knowledge chunking
All flespi documentation is stored in a single Weaviate class with the following content categories:
kb: sourced from our Knowledge Base;
blog: sourced from our Blog;
protocol: sourced from protocols usage specifics;
device: sourced from device descriptions on our site;
api: API methods sourced from REST API documentation;
fields_schema: item properties description, constructed from REST API documentation;
pvm: samples of PVM code, sourced from the internal repository and used to improve the quality of our PVM code generator.
Additionally, we have separate knowledge classes for content sourced from device manufacturers. Each manufacturer has a dedicated Weaviate class, and within each class, there are specific knowledge categories for each device. This setup allows us to retrieve device-specific knowledge effectively.
The knowledge content is split into chunks, each containing logically integral content. For content sourced from HTML pages, we usually start chunks when encountering header tags (h1, h2, h3, h4). Information from PDF files is segmented using the table of contents, dividing each chapter into dedicated chunks.
Each knowledge chunk has the following attributes:
category: knowledge category
source: link to the source page of this information
link: direct link to the source page with that information, usually the same as source but includes an anchor for better positioning on the page
title: source page title
content: textual information content
index: sequential index of the chunk, indexes are counted per each source page
tags: additional knowledge tags, if any
timestamp: knowledge actuality date
version: knowledge version
The system that retrieves, filters, and rearranges the chunks for RAG requires its own article to fully describe it. It is a crucial component of our AI platform's success, supporting different knowledge retrieval configurations for each category. These configurations include min and max chunks, information aging, sticky sources, whitelists, blacklists, duplicate blocking, re-ordering of chunks per source based on their index, and so on.
Here is a list of chunks with knowledge injected into the prompt when codi resolved the Segway Ninebot ‘R0’ command parsing issue. Distance refers to the semantic distance between the chunk and the context question generated by the classifier. A lower distance value indicates better relevance. A zero distance means the chunk was provided without semantic search:
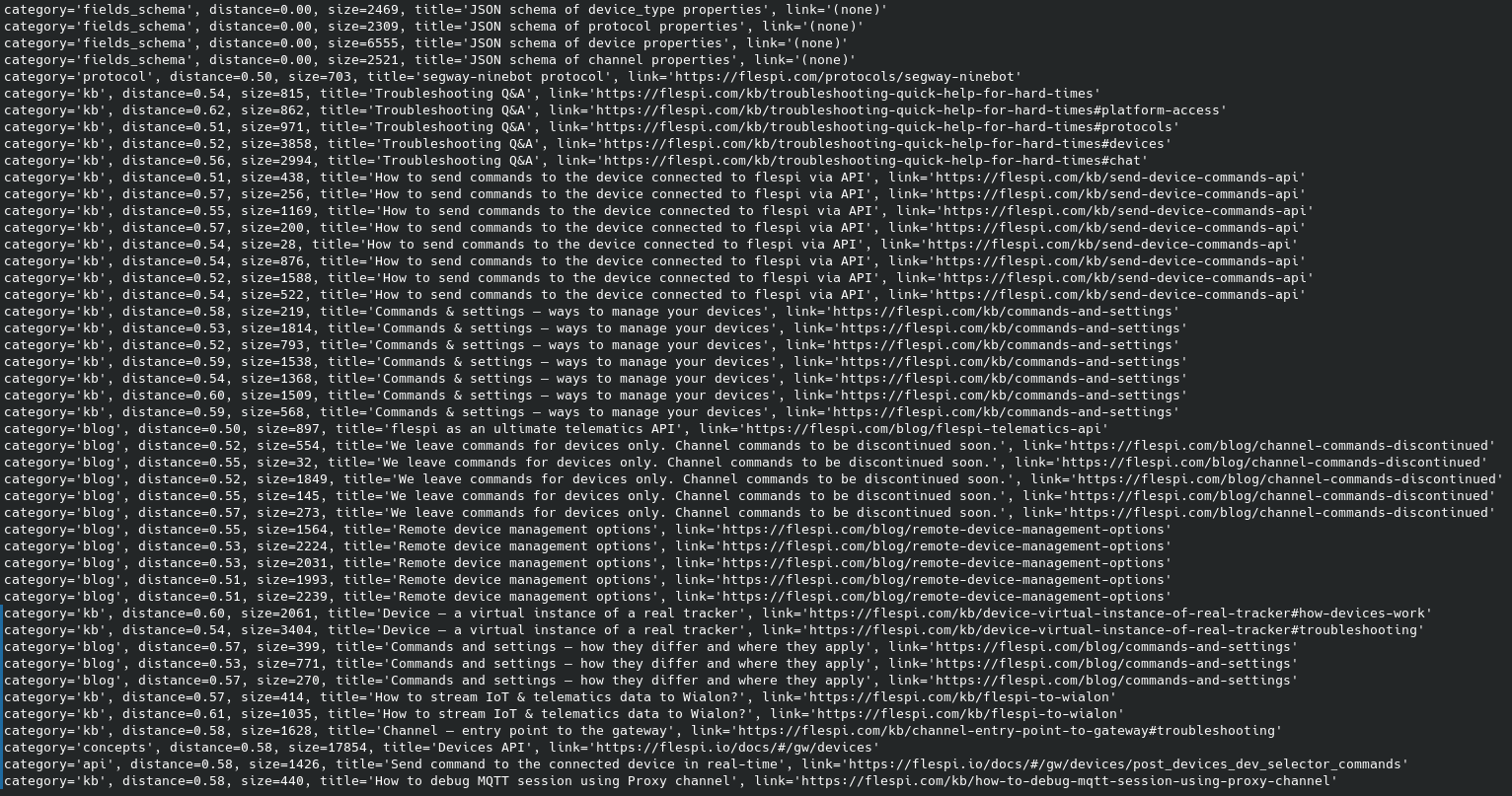
Knowledge content
When we ask a model to provide an answer, around 80% of the prompt is occupied by the knowledge content, with 20% used for instructions and data. In other words, the quality of the content in the documentation accounts for 80% of success.
In order to improve the quality of the documentation, we follow very simple rules:
Avoid ambiguity and controversial content.
Document everything we release, but in a concise manner.
Provide comprehensive how-to articles based on practical tasks.
Continuously improve the documentation content.
To remove ambiguity, we maintain API and KB documentation as our primary sources of knowledge, while information in the blog has an aging multiplier that increases the distance with each year.
We document every new or changed piece of platform functionality upon release. Even for small features, we find a few descriptive sentences and place them in the corresponding KB article.
Whenever we discover anything important during our daily work, we now share it with codi via the documentation. Good examples of this are the protocol usage specifics pages (e.g., Queclink, Concox, Teltonika, etc.), where engineers add notes about the particular behavior of various devices. This is the best source of specific intelligence for codi — and obviously not only for it.
When we encounter a question from our users in HelpBox that codi cannot answer, it’s the subject for us to publish a new 'How to...' style article in the KB. While our primary goal is to train codi to better answer similar questions in the future, it also offers a comprehensive overview of our platform's capabilities, which I hope will inspire you to try it in your applications as well.
And last but not least is the continuous documentation improvement. If we detect an incorrect answer generated by codi, we simply add a sentence or two to the KB documentation, and voilà, codi's knowledge is improved!
Here are a few tips for those writing documentation that will be used for AI response augmentation (RAG):
Structure it correctly with headers and chapters. Use a consistent style throughout the documentation.
Be concise and precise. Use simple words and short sentences.
Avoid tables, especially very large ones.
Remember that AI (at least currently in RAG) does not interpret images. Write all important information in text for AI, and include images only for human reference.
Use English only. AI can support any language if provided with documentation in English and a dictionary of specific terms for that language (if needed).
Edit and test. Ensure you have a tool that allows you to immediately test how your changes affect AI responses. Without such a tool, you are wandering in the dark.
What’s next
From the platform perspective, it now appears stabilized. Its architecture allows us to easily enhance it with additional knowledge, tools, and data.
We are considering adding more knowledge domains frequently used in telematics, such as EV vehicle know-hows, fuel control and the diversity of sensors used for it, BLE beacon applications, CAN bus-specific knowledge, and more. We might also load information about other platforms to provide better consulting services on the edge. For example, we have many common users with Wialon and regularly encounter Wialon-related questions in our HelpBox chat. Instead of directing users to support@wialon.com, it would be beneficial to try to answer their questions with AI, similar to how we currently handle device-specific knowledge from manufacturers.
The LLM release cycle is beyond our competence. I was absolutely happy with the “gpt-4-1106-preview” model in Q1 of this year. But now, comparing its answers with those of the latest models reveals significant improvements. We are eagerly awaiting smarter, quicker, and cheaper models that will be released this year or next, and we will test them on our platform as soon as they become available.
In the coming months, our efforts will be focused on content. We need to improve (rewrite) documentation for calculators and expressions, provide more use cases with webhooks, and comprehensively describe flespi UI tips and tricks. Also, we will write more complex how-to articles to cover various flespi applications.
Additionally, for each protocol or device we work with, we integrate its manual into our protocols knowledge system. This enables codi to assist with a growing variety of devices.
Another upcoming functionality is the unguided AI assistance service, where our users will be able to chat with AI regarding specific devices, calculators, or webhooks without the expectation that this communication will be reviewed by the flespi team. As we increasingly find satisfaction with the answers provided by codi, there may come a time when we trust it to operate autonomously.
One more functionality that may be implemented in the future is a fully autonomous protocol integration system based on provided protocols. You would simply upload a PDF containing the communication protocol, and the AI would generate the necessary PVM code to manage communication with devices. Most components of such a service are already accessible; we only need to consolidate them into a unified tool and ensure its functionality.
Stay tuned!