Would you believe if we said that you can have superior database experience with the new implementation of a long-forgotten technology?
Well, we do say this out loud.
You can have high-performance, high-availability, and high-reliability storage for frontend and backend services alike with… MQTT retained messages.
Please keep reading to recover from the puzzlement you might find yourself in.
The concept of HASD
Do you know that the very first database engines were hierarchical? Like IMS database from IBM released in 1960s for Apollo program.
The hierarchical databases are still unbeatable in terms of performance. And the most notable disadvantages compared to relational or key/value storage engines are the complexity of software development based on such DBMS and difficulties during data paths reorganization.
Today with the freshest technologies under the hood flespi reinvents the wheel and invites software engineers to try this oldest data organization technique but in a new way — faster, better, easier.
It’s shockingly new yet incredibly simple.
We propose to store data with retained messages inside MQTT Broker.
We named this technology — Hierarchical Asynchronous State Database (HASD) because:
The underlying storage concept is hierarchical and the storage hierarchy is defined by MQTT message topic. As with MQTT topics wildcards ‘+’ or ‘#’ it is possible to access the data in messages specifying only base part of the path or by using any topic selectors.
It is totally asynchronous same as MQTT protocol by its nature. Data integrity is controlled by special timestamp property of each message which can be passed by the client to the broker.
The database by its nature and organizational structure should represent the state of objects. Moreover, with each new message we automatically handle an event of state changes — i.e. no extra code for initialization/updates — just subscription which delivers you current state and next updates in the same way. Absolutely clean and simple code.
Because it is a database. Nobody ever thought about MQTT Broker as a database, but it perfectly matches the database definition in Wikipedia.
The concept of storing data in retained MQTT messages is not new and some projects are already relying on it. But for most engineers it is unknown and till this moment nobody has coined a name for it. And we just have. We are using this technology a lot inside flespi and keep getting more and more benefits, so we decided to share it with the world.
HASD is just a technology and theoretically, it is possible to power it with any MQTT Broker. But some special things like REST API, timestamp user property in messages, high throughput, and other features prevent it from being used with other MQTT Brokers than flespi.
HASD principle
The architecture of HASD is shown in the image below:
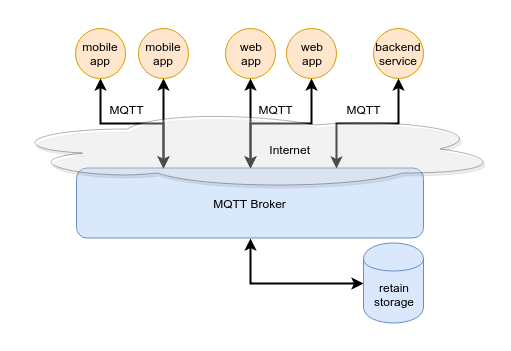
Basically, each service — either a frontend or a backend — maintains an MQTT session for communication with other services and at the same time for data update purposes.
Data is stored by publishing an MQTT message with retain=true and QoS=1 attributes into the corresponding topic, e.g. ‘cities/europe/belarus/minsk’ or ‘cities/europe/netherlands/groningen’.
Data is accessed by subscribing to the associated topic, like ‘cities/#’ to receive all cities or ‘cities/+/netherlands/#’ to receive all data for cities located in the Netherlands.
Alternatively to MQTT messages PUB/SUB it is also possible to update/access the data via REST API.
HASD use cases
The closest database engine to HASD by its operating model is redis. But redis is limited in storage capabilities, security, performance and is not focused on the state.
Redis, key-value, and relational databases are convenient for backend services operations and are not well-suited for clients over the Internet.
On the other hand, the current Internet (API-type) databases are not quite OK due to low performance for backend services operations.
HASD storage technology hits exactly in between.
The benefits of this technology are most evident when you are operating with objects state and for many projects it can be a seamless replacement of relational storage engine. At the same time, in some application areas using HASD technology might be inefficient.
- The most obvious HASD use case is for accessing the cloud state database from remote services — either web applications or mobile phones. Moreover, the same access technique is used by backend services as well. Simply speaking, you have some piece of state data that you want to synchronize between various users. And you need a secure connection to access this data over the Internet.
This is the main problem of storing data in a relational database — there is no normal way to securely access it remotely. In most cases you need a proxy that will control the security and implementing such proxy is not that easy. With HASD, the security is backed by SSL-ed MQTT connection based on access tokens and flexible read/write ACLs.
Imagine that you implemented a proxy that takes care of security. Next, you need to implement the API that will read and deliver to client objects state data and you also need to take care of data actuality for each connected client. Usually, this is implemented with sessions accumulating events on the backend for each particular client. From the backend side, it is backed either by database triggers generating events for each row modification or by a polling mechanism checking for any changes. Both options slow down with data volumes going up and become inconvenient.
Alternatively, with HASD all you need is to open just one MQTT session per each end user (client) and subscribe to appropriate topics. During subscription, all retained messages will be pushed by the MQTT broker into the session to maintain local cache as appropriate and upon new message arrival, the update will be delivered in absolutely the same manner. Did you get it? It’s that simple.
For backend services that do not need to store local cache and prefer to operate in the asynchronous mode like read some data, process it, and forget, it is possible to use either well-known HTTP REST API for data extraction or special MQTT 5.0 features such as subscription ID and subscription flags.
- Another popular use case for HASD is when you need asynchronous performance beyond the capabilities of a relational database that is limited (due to its nature) by the transactions-per-second rate. With HASD you can generate tens or even hundreds of thousands of update requests per second and MQTT broker together with its storage system will easily handle this load sorting out the latest actual data state.
- One more interesting use case is session access from a mobile network when the client IP address is changing all the time. Thanks to the possibility to set an expiration period for MQTT sessions it is rather easy to resume session even after reconnect with zero data loss.
HASD benefits
The benefits of using HASD will lie in the plane of implementation simplicity:
Same data access methods for backend and remote (frontend or mobile) applications
Same data access method for initializing state data and keeping it actual
You need only one MQTT session for your application to communicate with the database and optionally with other services
As a bonus, you get the possibility to operate backend service in an unusual way — there is no need for them to be accessed directly by client applications — now you can run multiple instances of backend services also subscribing to special command topics and publishing answers to them as MQTT messages. Together with shared group subscriptions feature you get High-Availability and Load-Balancing of your backend processes immediately with zero complications.
Implementation specifics
To work with HASD you need an MQTT client library. Plus, optionally, a special HASD wrapper library to maintain local cache and correctly merge objects state update information.
Additional HASD library is fully optional as you may work with MQTT directly or via HTTP API. As time goes and more projects come to use this technology, more simplification wrappers will appear.
You may use an MQTT 3.x client as the most popular but to experience the full power of HASD together with correct behavior during the merge of state updates by special timestamp property you have to use MQTT 5.0 client library.
For backend development with python, the best MQTT 5.0 library is gmqtt. It is the first python library supporting MQTT 5.0 targeted at high messages throughput, used in multiple projects, and backed up by Gurtam.
For javascript frontend/backend development the best library will be MQTT.js. The integration of 5.0 protocol is backed by flespi developers and we are using it quite a lot in our frontend applications to receive high volumes of data.
For C embedded/backend developments you may use eclipse paho. For small/medium data volumes it is quite good. For large volumes of messages, like few millions of messages per minute, you may have some problems upon connections/disconnections.
For other programming languages please check this list.
The best tool for debugging HASD will be MQTT Board that implements all the benefits of MQTT 5.0 protocol.
***
You know what really matters in software development?
Time.
Time to develop the first version, time to maintain and upgrade with new features, time to install it and so on.
HASD is a time-saver.
By using HASD technology for maintaining objects state the development process is much faster and simpler including minimal efforts for installation.
This matters a lot.
We already tried it, got plenty of benefits, and are now popularizing this technology within the developers' community.
Give it a try in one of your pilot projects and you will see for yourself how easy and fast the development process can be.