In this article, I will share our experience in key/value time series database design. The flespi database consists of multiple layers, starting from the API part responsible for receiving, parsing, and queuing commands to the database engine and database engine by itself. Today I will drill directly into the database engine as the most interesting part.
Here is the layer structure of the flespi database:
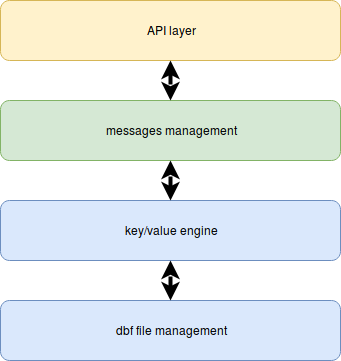
dbf file management is a simple and efficient low-level library for accessing memory-mapped database files. We named this technology dbf for "database file". It contains routines for allocating and freeing database memory backed by a file. The operational unit for memory allocation here is a page, and it is possible to allocate or free continuous block of memory X pages in size. At this stage, it is important to select adequate page size. Based on our experiments and implementation of the next layer — key/value engine — for 10K RPM SATA drives the best page size falls between 16KB and 256KB. Less than 16KB will lead to too many drive searches for data access while more than 256KB is usually inefficient due to many holes in data.
key/value engine is the simplest (probably) implementation of the key/value storage access. It relies on dbf file management to place its data on the pages. Two years ago we implemented a B-Tree based key/value library, and now we switch to the B+Tree. Later I will cover the reasons and results we achieved with this upgrade. The engine itself has just a few functions: to store value for a key, delete it, and access methods. The dbf file backs up all data and metadata. And it is possible to store as many trees as you need.
On top goes the messages management. This part already got a lot of attention during 2017Q4 and 2018Q1, and now we are running the third generation of this system supporting various storage strategies described in the storage module announcement. This part is already squeezed and optimized based on our experiences and tests. How to achieve even better performance? Yep, the only way (expect upgrading hardware) is to drill down to the next layer — the key/value engine and make it better.
Before I continue to B-Tree, let me say a few words about the database engine itself. Initially, when we designed it, we had only two types of objects to store in the database: containers and abques. And the messages management layer implementation was customized towards the needs of these two storage types. You can read how we did this a year ago in this article.
This year we implemented CDNs — cloud file storage with an external download link. Comparing to normal telemetry the data from IoT devices files can be huge — up to 128MB of binary size. We also store them in the database, but split large files into small 8MB chunks and store them as conventional key/value messages. So far there was almost nothing to add to the messages management layers, just the API part that should know how to split, store, and merge back the files data. What’s more, the design allows storing large volumes of streaming video content! We can create own Youtube if we need. And this is all based on a simple key/value database engine!
The second addition to the flespi database was an internal thing — the possibility to store MQTT retained messages. This one is the opposite to CDN — the storage elements are tiny, but the quantity can be huge. For retained messages storage we need not only to store them fast but, at the same time, we should be able to retrieve them at the moment MQTT session subscribes to a topic. And this can be quite tricky, because with a subscription to the topic 'a/b/+/4' we need to return messages with a topic like: 'a/b/c/4', 'a/b/1/4', etc. So we need to implement an internal index.
What we've done is we implemented a btree inside another btree. In the case above for the topic 'a/b/c' we store the btree responsible for 'b/c' path under key 'a' and in that btree under key 'b' we store another btree responsible for further path in which under 'c' key we finally store the MQTT message payload.
In such scenario, we end up with many trees with few elements. To store them efficiently we reduced the page size from 256KB to 16KB, because each tree needs at least one dedicated page in the database for its data.
As you can notice, the requirements for the database engine have slightly changed from what we initially had. Even two years ago when we tested the initial implementation of the B-Tree key/value engine, we noticed that once the database exceeds the size of server cache virtual RAM (200 GB size on 64GB RAM server), access to it may become slow and sometimes requires up to a few minutes to warm-up the cache. This is due to a B-Tree design where each node contains data, and when you sequentially read messages, you need to travel from node to node. Each node may sit on a different database page thus requesting the inherently slow disk seek operation.
At these early days we already saw the limitation and made a resolution — we need to change the implementation of B-Tree to something more usable in such cases, e.g., B+Tree. But up until this moment, the performance of the B-Tree implementation was good enough, so we’ve been focusing on other major things — like telematics hub, MQTT broker, etc. But now that we have finished most of them, we can get back to our precious — the database engine.
We have recently implemented the new B+Tree key/value engine based on extensive modern experience, and so far the results are excellent. Now we are not limited to the size of the database anymore, and it works extremely efficiently with any size of the RAM. We even tested it from the MQTT broker side by storing all messages that we receive from Wialon Hosting as retained with each parameter stored in a separate topic. We were getting 20,000 messages per second with each message containing 20 to 100 different parameters, which meant that we stored in the database one million retained messages per second. On a single SATA drive! It passed the tests and was working without a hitch for hours replying to read requests in an instant even at the peak load.
Now we can move further — we are no longer limited to the size of the working dataset and can place plenty of data on cheap 2U SATA equipped servers.