Recently, I’ve posted an article with the description of flespi platform architecture describing MDB — our own database for storing telematics data — as one of the most important systems. We use it for storing messages from devices, channel logs, command execution results and in many other cases where large volumes of unstructured historical data records are operated.
When engineering database system for flespi we were primarily committed to performance, reliability and reasonable prices. Exactly in this order — performance was and still is our top priority.

We evaluate performance by the number of messages per second we can fetch from a database and its variations over time when the database contains hundreds and thousands of terabytes of data. We also consider a delay we have for the operation, i.e. how many random operations per second we can have with and without constant load.
Our regular use case is that hundreds of thousands of devices send messages with a timestamp and 100-900 bytes of useful payload. These messages need to be sorted by device, then sorted again by time for this device, and finally stored in the database and read when there is a need.
Our performance target is to be able to fetch 500,000 messages per second in a block mode with LAN connectivity to the database and 100,000 messages per second in a random access mode when we can have 10,000 devices each containing 10 messages. From the disk storage, not from the cache, and with SATA drives (for a reasonable price).
In search of the ideal database system
We tested everything we’d found on the Internet — from non-relational DBMS like Oracle Berkeley DB, Symas LMDB, LevelDB to normal SQL-based RDBMS like PostgreSQL. We tested them with our special use case that we discovered while operating with a hundred thousands of devices in our Wialon Data Center and thousands of users and automation tools running reports and consuming large datasets.
We made a conclusion that all these libraries are really good when used on a small to medium dataset but upon reaching hundreds of terabytes they started to behave either slow or unstable. So we had no other choice but to implement own database management system — the one that fits all our requirements. Here is its scheme:
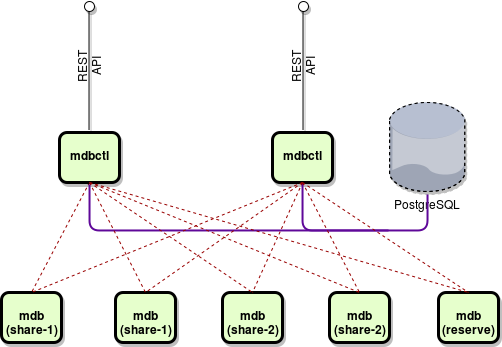
We split database management system into two components:
- mdbctl processes — designed to provide HTTP REST API for database users, store metadata in PostgreSQL database, and provide transparent connection to mdb nodes that store actual data;
- mdb nodes — designed to store telematics data in mmap-backed database file and synchronize its contents between other nodes upon request;
In PostgreSQL database we store metadata like shares, nodes information, and storage items distribution among shares.
Advanced storage capacity
Share is a special term for a group of items which store data in one mdb database. Each mdb process (node) can service only one share. This helps to distribute the storage capacity and load over additional nodes. Each node servicing share contains a complete copy of data for a given share. When we read operations we split the load between all the nodes for the share. When we write an operation we do it on all the nodes servicing a given share simultaneously. This is like a database level RAID-10. And we can specify 2, 3 or even 5 nodes for a share and maintain the high level of data duplicates. Actually, for the production system, we use 2-4 nodes per share for customers depending on the SLA level.
Some nodes are spare and are running in reserve mode. As soon as the system detects that one share does not have enough assigned nodes, it will address a spare nodes pool, assign a node to the share and instruct it to connect to one of the normal nodes for data synchronization. Everything is done in the background and automatically with no need for any action from the operator.
On the mdb nodes themselves, we store data in mmap-ed files that consist of data pages. We use page size of 256KB and each data page is assigned to one of our storage systems. Storage system is implemented based on the type of data we use. For telematics data (historical events), we use very simple mmaped btree — we call it a container. For message buffers, we use the same btree with a special mdbctl process synchronization mechanism on top of it — we call it abque (asynchronous batch queue). For pictures, video streams, and tachograph data from devices we use totally different storage system.
For channels, we store messages and delivered commands in abque (so one can easily detect similarity in their API).Channel logs are stored in containers with a little different API structure.
As for hardware, we use 2U servers equipped with 2x120GB SSD in RAID-10 for the system and cache and 6x2000GB SATA for database storage. Each database server contains 6 mdb nodes. We can easily lose one/two drives or even one/two servers without any impact on data integrity. As soon as there is at least one synchronized node with a full dataset for a given share we are ok.
There can be any quantity of mdbctl processes servicing REST requests. One of these processes is automatically voted as primary and controls nodes distribution among shares.
Currently, we maintain 2 application servers inside flespi platform — each running some redundant processes along with mdbctl — and 4 database servers with up to 24 mdb processes. 4 database servers are our reserve. Actually, we do not need that much but we regularly run some performance tests and we have already burned few SATA drives there.
In the near future after we finish the work with flespi gateway module we would like to provide platform users with the possibility to have direct access to mdb system at least for telematics data storage because the performance level we’ve achieved with such a low price can be offered by no other cloud-based system. Google Cloud, Amazon AWS, MS Azure or any custom cloud storage system will be limited in performance with a large dataset especially when we speak about random IOps. Once we release public API for MDB system feel free to push it to the limits and enjoy its new possibilities for your solutions.
Disclaimer: flespi database system has moved to next generation: from B-Tree to B+Tree.