Having shown some examples of PVM usage in plugins, we are ready to provide more info about PVM as technology and help you understand how to use it.
Historical context
A long time ago, in a galaxy far, far away… we at Gurtam started developing numerous scripts in TCL to parse the data received from the various tracking devices connected to Wialon. Every new integrated protocol led us to new common functions or programmatic tricks to write code more and more effectively. But still, every time we ended up with a script written using a general-purpose programming language. Thus, every time we needed to deal with any protocol-specific issue or enhancement, we had to go back to the script code, understand its abstractions and find out how they correspond to the device protocol specification, and then use these abstractions to enhance protocol logic in a script.
After a while (several years ago), we started developing the flespi platform. And decided to accumulate all our protocols-related experience in a new set of tools helping us to do protocol integration work much easier, faster, and straightforward.
That’s how PVM was born.
PVM syntax
First of all, PVM is a programming language. Further reading of this article assumes that you are already familiar with any general-purpose programming language like JavaScript, Python, C, C++, Java, etc.
Like any programming language, PVM contains syntactical constructions for variables, operators, numbers, string literals, functions, and other abstractions which you may use to define the data transformation algorithm.
What is a PVM program
Unlike most popular general-purpose programming languages, PVM was designed to write declarative code. It means that PVM code says not “do this, then that”, but declares “what data we have” and “how it should look at the output”.
Declarative code is easy to read and understand. On the other hand, it requires a lot of abstractions in the language to declare (almost) all possible practical cases.
Data conversion and transformation is a very practical task and the primary reason for PVM existence. Some cases cannot be described effectively with declarative code, that’s why even though PVM code looks declarative, it's still an imperative code. As a result, PVM has a very expressive syntax to declare data format and at the same time, it has variables, loops, conditions, etc. to be able to handle all possible data transformation cases with imperative code.
Main conventions
- PVM is a case-sensitive language. unset and UnSet are not the same thing
- Only English symbols can be used as identifiers. Full Unicode support is available only in "string literals"
- Nested elements are separated from the parent with increased indentation (just like in Python), and only horizontal tabulation symbol (0x09 ASCII char, \t) can be used for it
- C++-style comments: /* multiline comment */ and // one-line comment
Structure of a PVM program
Thanks to its declarative look, the PVM program can be treated as structured data in text form (like an XML or YAML file, for example). In other words, the PVM program is knowledge written in structured text form about how data should be parsed and transformed.
The PVM code is structured on two levels:
- the whole source code is a tree (set of linked nodes)
- each tree node consists of one or more elements of a more basic level.
Let’s look at these levels in more detail.
Every software engineer knows that to represent a tree data structure, you need a set of tree node objects and parent/child relationships between them (without loops obviously). Some tree nodes are simple (also called leaf nodes) and some are complex, which means they contain children nodes (each of them is also simple or complex).
So, a tree of PVM code is constructed from two types of nodes: chain (which is a simple node) and section (complex node). Unlike in generic tree data structure, the section node, in addition to a set of children, also contains a subject node, which is always a chain. It can be treated as a dedicated child of that section node.
To understand it better, here is a diagram of the PVM tree example:
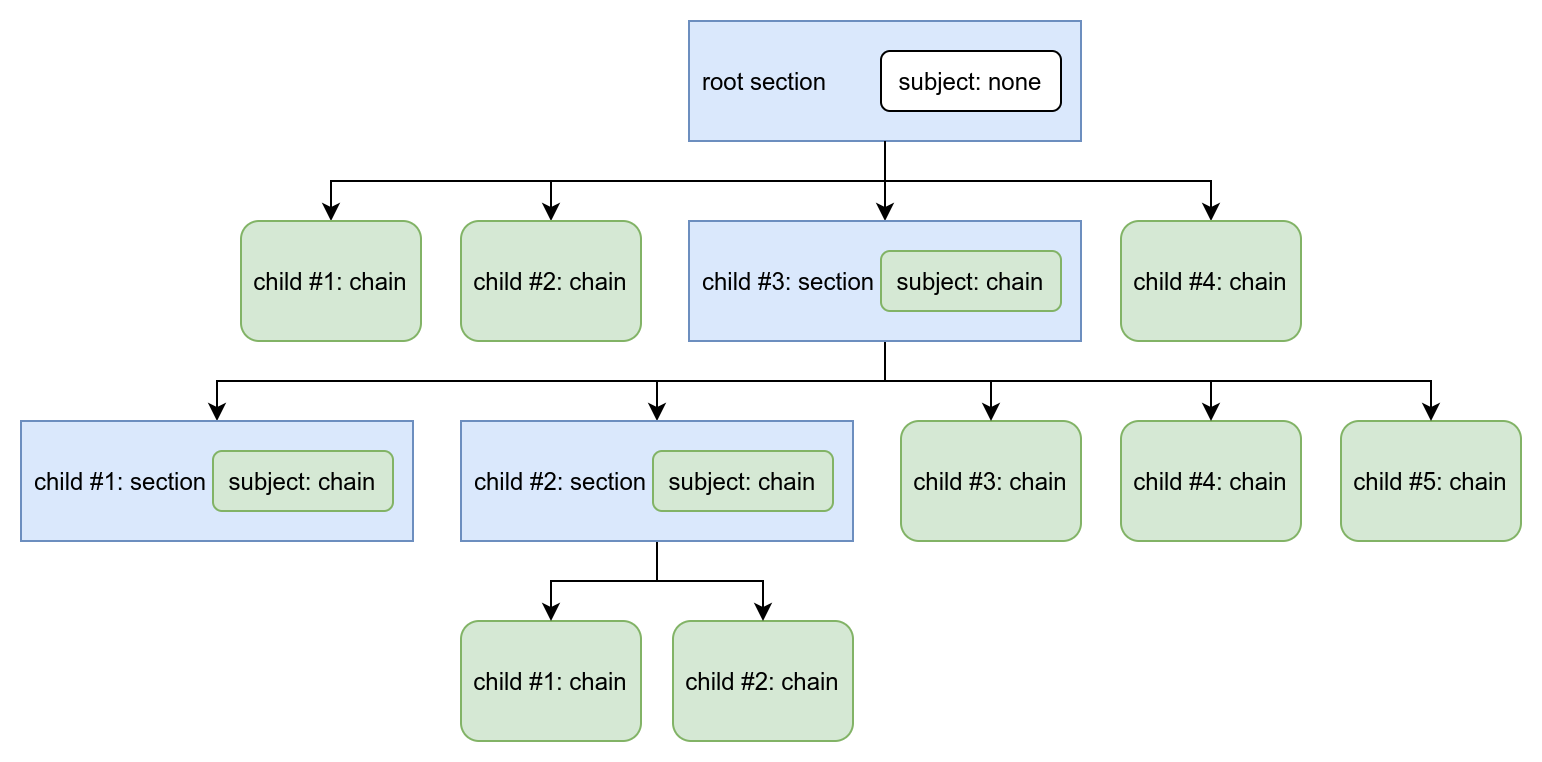
And here is the same PVM tree as a source code:
child #1: chain
child #2: chain
child #3: section subject chain:
child #1: section subject chain:
pass // see below
child #2: section subject chain:
child #1: chain
child #2: chain
child #3: chain
child #4: chain
child #5: chain
child #4: chain
To represent a PVM tree in text form, the chain should be just a line of text, and the section should be written as its subject (which is also a chain) with the colon char (“:”) at the end of the line and increased indentation for its children. If a section has no children, a special word pass should be used with proper indentation. Just like in Python:
section without children:
pass
Now it’s time to see the structure of a chain. In PVM the chain is a non-empty ordered list of chain links. Each chain link contains an atomic syntactic element of the PVM language, like a variable, operator, number, a string literal, expression, and others. When you write a chain in a PVM source code, its chain links are joined using the arrow symbols: ==>
Here are three examples of the PVM chains with one or several chain links:
one-link chain
chain with ==> two chain links
link1 ==> link2 ==> link3 ==> link4 ==> link5
That’s how every PVM program is structured.
Data flow through the chain
Chains were developed to denote data flow, i.e. in the first chain link we’re fetching a piece of data, in the next chain link we’re checking or converting it, then in the next chain link we’re using this converted value to store it somewhere else, and so on, in the direction of arrows.
If the chain loaded a value in some chain link, it should save or consume that value somewhere in the following sections of the chain. This restriction helps split a big parsing task into a set of small basic tasks, which helps write clean code.
Atomic syntactic elements of PVM
Below is a list of common syntactic elements used to denote atomic parts of the program, like variables, numbers, string literals, etc.
- Number: For example, 0, 1, -100, 3.14, 0x42
Used to denote a constant numeric value. Only decimal (with optional fraction part) and hex form are allowed. - String: One of "string literal", `fixed string literal`
Used to denote a string — a sequence of chars of arbitrary length. Note that any byte can be used as a char, so string values can be used to store binary data. Use escape-sequences like \xFF for that. In contrast, fixed string literals can be used to easily write a string containing a lot of chars which you usually \-escape in usual strings, like double-quote and backslash. In the fixed strings only the backquote char itself ( ` ) should be escaped with doubling it. - Binary: One of <"binary string with zero byte" 00>, <01 0203>
Used to denote fixed binary or string data with embedded non-text bytes in HEX form. In most cases is interchangeable with string literals. - Constant: One of true, false, null
Used to denote two possible boolean values and a special null value in JSON - Word: For example, if, switch, repeat, any_word_without_spaces, pvm4parsing, camelCaseWord
Used to denote execution control operators (loops, conditions, mappings, conversions, etc) - Variable: For example, $var
Used to store intermediate results in calculations or other data transformations. See the next section for the available variable types. Note that variable types are strictly traced. - Property: For example, .fixed_property.name
Note the dot char at the beginning. Used to denote a fixed JSON object property name. Note that dots in the middle of the property name are treated “as is”, without any json-path logic to access sub-objects. - Varprop: For example, {"prop with space"}, {$variable_property_name}
Used to denote a JSON object property whose name contains spaces (thus it can’t be represented as a property above), or property with variadic name, whose exact name is known only at the runtime stage. - Type: For example, %uint32
Used to convert value types in chains, or to read/write binary data fields. - Param: #position.latitude
Used to denote a resulting JSON object (message) property - Attr: [key="value", 2, 3, error=false]
Used to denote parameters for control operators like loops, to specify values mappings, etc... - Label: @label_word
Used to group a set of actions to be called from other places. Just like a function or procedure in general-purpose programming languages.
Elements behavior in the chain
Most elements carry different meanings depending on their position in the chain. For example, using a $variable in the first chain link will read the variable value and provide it to the next chain links, providing reading variable logic:
$answer ==> <use variable value here>
However, using the same $variable in the non-first chain link will save value to the left of the variable into it, providing variable storing logic:
42 ==> $answer
There might be several $variables in a chain, and the left value will be copied into all variables:
42 ==> $answer ==> $for ==> $the ==> $ultimate ==> $question
Note that evaluations are available only in the first link.
The same first/non-first logic applies to other elements denoting a value, like .properties, {$varprops}, and %types.
Context
Besides position, elements can carry different meanings depending on usage context.
The context is a set of rules for the chain that defines a set of possible operations for each chain link. There is a base context called generic — it contains base operations like mathematical expressions, flow control operators (conditions, loop), variables, value and type conversions. PVM also provides a set of contexts derived from generic — for example, json_object and binary. They provide special operations related to accessing data of the associated type (JSON objects and binary data respectively) besides usual generic actions.
The context is a virtual entity — a programmer should track it in his head and understand it while reading/writing a PVM code. Fortunately, after some practice, it does not require much effort. PVM is intended to be easily readable by humans.
The context usually changes automatically when moving through the chain links, from specific (json_object or binary) in the first chain link to generic for the rest. Thus, reading a JSON object property using the .property element (from json_object context) is available only in the first chain link:
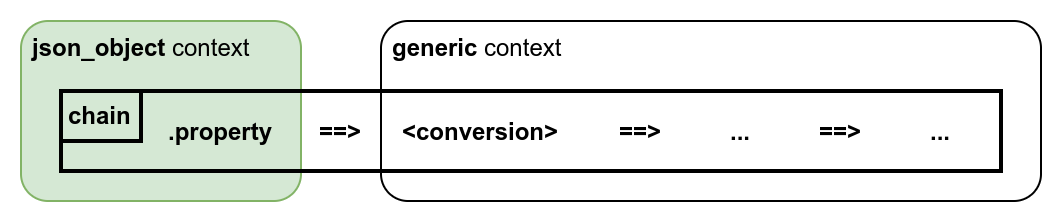
Also, some elements can change the context for the rest of the chain or for the whole section if placed in the section subject. It can be used, for example, to parse string/binary data from a JSON property in the input-section:
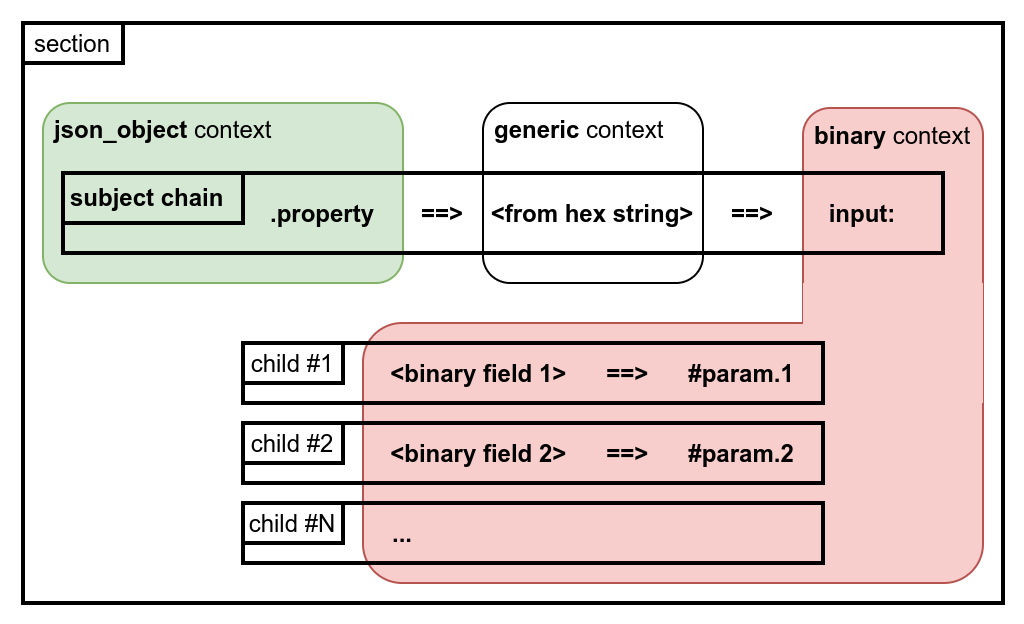
You should only know the starting context for the PVM code, and how it’s changing by moving through the chain, to track it and understand. All subsequent contexts can be easily tracked from the PVM code.
PVM runtime
PVM actually is a set of tools, not only a programming language. To be able to solve data transformation tasks, there should be a runtime (software) able to execute PVM code against the data to transform it.
PVM compiler
To execute PVM code it should be compiled (translated) into bytecode — a set of low-level instructions of some virtual machine to be applied to the data to transform it. By the way, the name PVM stands for Parsing Virtual Machine.
The bytecode is an internal representation of the PVM code. You can think about it as a .NET Assembly file or Java Class file with JVM bytecode. It is stored internally in the flespi platform entities you create (plugins, for example).
The main purpose of the PVM compiler is to parse your PVM code according to the rules in the previous sections of this document. During this process, the PVM code is checked for validity and converted into a bytecode automatically.
The whole process is performed automatically when you create or update your plugins with PVM code.
Mainstack
During the PVM bytecode execution, all values processed by the chains are stored in the stack as intermediate storage. This stack is called “mainstack” because there are several more stack structures at runtime (see below). For example, this chain
$variable * 10 ==> $variable
will produce the following stack operations:
- Push value of the $variable
- Push value 10
- Multiply two values on the stack, so 2 values will be removed from the mainstack and one will be pushed instead
- Take one value from the mainstack to save it into the $variable
The PVM compiler will check that mainstack is left in the same state after every chain execution. So you can’t leave calculation results without saving them in the variable or resulting message parameter.
Basic value types
The PVM basic value types are based on JSON basic types:
- number to operate with numeric values
- string to contain fixed text or binary information
- boolean to denote a true or false value
- null to denote special null value in JSON
In runtime (when PVM code is executing), the number values are stored in one of the three variants — as int64_t, uint64_t, or double C/C++ value. One of the main PVM tasks is to parse binary data, and the double value type lacks the accuracy to represent all possible 64-bit integer values.
Those internal number type variants are interchangeable and transparently convert between each other in mathematical evaluations. Note that after saving into a JSON object (into a resulting message in particular) all number values will be converted into double, according to the JSON specification.
Complex data types
Most programming languages provide you with some complex data types like arrays, lists, hashtables, structures, classes, etc. They're obviously required to write arbitrary algorithms but our practice shows that basic value types are enough to work with almost any data parsing or transformation logic.
The only complex data PVM is working with is what it gets for input (JSON message in case of plugins or binary data in channels), and produces as an output (JSON message too). To work with these, there is a concept of istack — a stack of complex input data structures. It’s a physical representation of a context concept from the sections above.
As I wrote before, the PVM code in plugins starts with a json_object context. This means that when the PVM code in the plugin starts to execute, it has a JSON object (message to transform) entry on the istack. Thus, all property reading elements like .property or {$varprop} are operating with this JSON object. If it’s a basic JSON value (number, string, boolean, null), it can be placed on the mainstack as an appropriately typed value. And if it’s an object or an array, it should be placed as a new entry on the istack using special syntactical construction starting a new section in the PVM code. So, in that section, the same .property or {$varprop} elements will work with the top of istack, i.e. with the object/array fetched on the previous stage. And right after the section that object/array will be removed from the istack and the next code will work again with the first JSON object (message). Consider this example:
// message is on top of istack: {"ident":"device-ident","obj":{"property":42}}
.obj ==> object:
// part of the message on top of istack: {"property":42}
.property[number] ==> #answer // will contain value 42
// and again message on top of istack: {"ident":"device-ident","obj":{"property":42}}
...The same thing for the binary data — you can parse it in a section in the PVM source code with parsing logic:
// message on top of istack: {"ident":"device-ident","data":"01000200"}
.data[string] ==> %hexstr ==> input:
// now on top of istack: 4 bytes of binary data <01 00 02 00>
%uint16 ==> #first.two.bytes // value: 0x0001, i.e. 1
%uint16 ==> #second.two.bytes // value: 0x0002, i.e. 2
// and again message on top of istack: {"ident":"device-ident","data":"01000200"}
...Switching between data contexts becomes intuitive with PVM.
Control operators in PVM
Despite the declarative look, PVM is an imperative programming language, executing its code from the top to bottom, and every chain from the left to the right (in the direction of the ==> arrows). Programmers need operators to control execution flow — condition and loop.
Condition
There are two operators for condition — if and switch. Both of them require writing a new section in code to work. Here is an example of the if operator:
if <condition>:
<actions-if-...>
<...-condition …>
<...-becomes-true>
Of course, there are an else and else-if (elif) branches for multiple conditions:
if <condition-1>:
<actions-if-condition-1-becomes-true>
elif <condition-2>:
<actions-if-condition-2-becomes-true>
...
elif <condition-N>:
<actions-if-condition-N-becomes-true>
else:
<actions-if-all-conditions-becomes-false>
There might be any boolean-resulting expression in place of <condition>, as in any general-purpose programming language. For example:
if .temperature < 0:
"Sub-Zero" ==> #wins
Boolean variables can be also used:
.property[boolean] ==> $variable
...
if $variable:
"property is true" ==> #answer
Note that there is no implicit types conversion to boolean. Unlike JavaScript and C/C++, 0 and "" (empty string) will not be treated as false values. There is no "falsy"/"truthy" concept in PVM.
The switch operator can also be used as a special form of the conditional operator. It’s usable when you have one value and many variants of action to do depending on that value:
.property[number] ==> $property
switch[$property]:
1:
<actions-if-$property-is-1>
2, 3:
<actions-if-$property-is-2-or-3>
7 ... 10:
<actions-if-$property-is-from-7-to-10>
default:
<actions-for-all-other-values-of-$property>
Note that every switch case is obvious and can be represented with a set of possible values, or even with a range. The default branch is optional.
Loop
Out practice has shown that one kind of loop operator is enough in most cases. In PVM it’s a repeat[N] placed in the section subject. It repeats the code in section N times. N can be any expression with number type:
repeat[$count]:
<loop-body-repeated-$count-times>
In addition to N, you can specify a counter-variable that will be incremented automatically for each iteration and its starting value:
repeat[$count, counter=$i, from=1]:
<loop-body-repeated-$count-times>
The repeat loop operator has a special form in the binary context (when you parse binary data). It will be covered in the next article.
Math operators in PVM
PVM supports the following mathematical functions:
math.round, math.floor, math.ceil, math.abs, math.acos, math.asin, math.atan, math.cos, math.exp, math.log, math.log2, math.log10, math.sin, math.sqrt, math.tan, math.trunc, math.pow[...]
Here's an example of how to apply these math functions in PVM code:
.battery.level ==> math.round ==> #battery.level
.value ==> math.pow[.power] ==> #value_in_power
***
If you are reading this, you are as close to understanding PVM as one can be. We know there is a lot of new information and it may take some time and effort to grasp it. But if you believe plugins with PVM can solve your tasks, give it a try, and don’t hesitate to contact us in the HelpBox chat with any related questions.
P.S. This is the first-ever public documentation for PVM and it might be somewhat lengthy and imperfect. However, we clearly see the benefits this technology can bring to the telematics and IoT community and are relentlessly working on making both the engine itself and the docs better. If you spot the things that require clarification, please let us know and we’ll elaborate on them.
P.P.S. PVM is still actively developing so we may occasionally introduce some changes to the syntax. This may lead to compilation errors and failure to save the current PVM code in your plugins. We promise to be as careful as possible and will notify you about any upcoming changes on the forum.