Whenever you have a plan to implement a data collection system, you should envision how to access the data. Loads of data. flespi engineers have a rich background in big data analyses — we stood at the foundation of the Wialon Data Center team — the one that maintains the core of the Wialon Hosting platform across multiple datacenters and oversees its communication with 1mln+ connected GPS devices collecting gigabytes of telemetry information each day.
If you can access it, you can use it
When we started developing flespi as a telematics backend, we clearly understood that it will have to power the platforms handling hundreds of thousands of devices from thousands of users generating gigabytes of information each minute. Another thing we realized was that there is no sense in collecting or storing data if one cannot easily access it. Moreover, rarely would anyone need raw data — rather, everybody wants to execute reports, retrieve the calculated information, receive real-time notifications about the events, and so on.
Crossing geofence boundaries, fuelings and fuel thefts, operations of various sensors, speed control — each application area has its specific “customary” calculations to be performed in reports and notifications. The more countries and spheres you are providing a platform to, the more flexibility you need to provide.
Two approaches to reporting

There are two approaches to implementing a report engine:
On-demand calculation — the simplest and the easiest to implement and use.
Real-time precalculation — more advanced, usually more complex to implement and more demanding to the platform resources.
On-demand calculation
With the on-demand calculation engines once the user wants to execute a report over the stored information he calls the corresponding API call (or clicks the button in the application) passing all the report configuration into the report engine and triggering the report engine operation.
There are also two possible implementations of on-demand report engines.
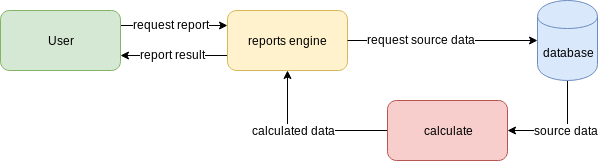
First performs all the calculations in real-time and returns the completely calculated result in response to the API call. This type of implementation should work just fine on moderate data volumes but will require high report engine performance for large datasets, because otherwise the caller can be blocked for several minutes — until the report calculation is finished. The benefit of this approach is simplicity — both in implementation and usage.
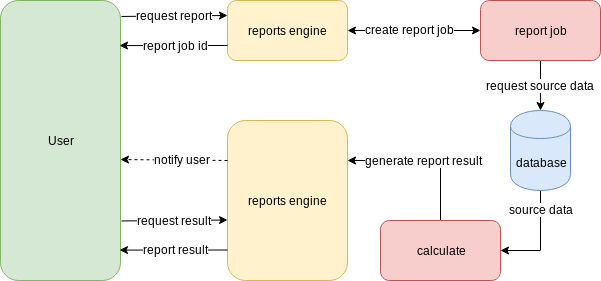
Second type of implementation implies returning an id (in response to the API call) for the job assigned to run this report. The actual report calculation is done in the background and once completed the caller is notified and gets access to the results. With such an approach, the report calculation job can run even hours (without blocking the caller), calculated reports can be stored and accessed later, and it’s possible to control the reports generation process from the outside. The drawback is the complexity of notifying the caller about the job completion.
The biggest problem with the on-demand report calculation approach is that it almost instantly becomes outdated either due to change in the source data or change in reports calculation algorithms. This is especially noticeable in reports covering a large date range. And if you look in the changelog of any mature telematics platform, you will notice that most updates relate to reports calculation engine. Which is absolutely logical.
Another almost insurmountable problem is the volume of data you may analyze — the bigger the time range you want to analyze, the more time, CPU, and RAM it will take to complete. This limits the maximum viable range selection to about a month in most popular systems, up to a year in good systems and up to a few years in the best ones. Knowing that a report over a year’s period for one object may require retrieving and processing a few gigabytes of information and may run for a few minutes, it may be practically impossible to calculate a report for a fleet of hundreds of vehicles.
Real-time precalculation
Another report engine implementation approach is to perform pre-calculation in real-time as the new telemetry data arrives and store the results in an intermediate database. Once the user requests a report, the system will almost instantly provide him with the results because everything is prepared in advance. Most modern analytical systems and databases (e.g. Google Analytics) use this approach.
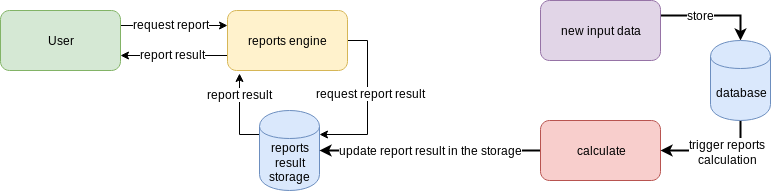
The key benefit of pre-calculation is high performance when accessing report results — everything is ready for the whole period and may be instantly delivered to the user.
The drawbacks are the complexity of implementation and the load generated by the system in day-to-day usage — just imagine that you need to constantly calculate everything even if the results of the calculation will never be requested by the user.
Regarding the implementation complexity — telemetry information from GPS devices and IoT sensors is by definition time-series data and thus can be precalculated by existing analytics engines and time-series databases. The difference between telematics data and ordinary time-series data lays in the number of calculation parameters that can be huge for the former type. Also, geospatial position information is of special attention in telematics since it should be matched against the geofences provided by the user. These specifics pose serious difficulties for standard database engines thus forcing every telematics platform developer to implement their own report engine.

Quintessence: flespi report engine
Having gone through years of Wialon development, we came to realize that next time we should stick to real-time data pre-calculation approach to reports execution. Such an approach was implemented in the flespi analytics engine. We tried to pick the best of the two worlds and pack it in flespi:
Flespi can execute reports in both ways. It is possible to use the on-demand mode — pass the report configuration to the database engine which will calculate and provide report results over the currently stored data. At the same time, the same reports can be configured to run real-time in the background and give the user instant access to any report results. Our users are free to select an access method depending on the task at hand.
Reports in flespi are highly configurable. We created the platform and provide our users with building blocks to implement almost any algorithm. If something is not there, like fuel calculations over floating fuel level sensors or external fuel card systems integration, we provide a mechanism to plug in any additional logic into flespi reports and inject custom data into generated reports.
On top of the precalculation-based report engine, we also provide the events and notifications engine — all the events and updates are reported into MQTT and can be consumed by 3rd party for further processing (SMS, email notifications or whatever).
flespi analytics engine is implemented in pure C and is lightning fast. It also allows storing pre-calculated reports for up to 10 years. Just imagine — 10 years’ worth of historical information accessible any time in a few seconds or even milliseconds… And to be even more flexible we provide our users with the possibility to run reports over precalculated reports.
***
In one of my next articles, I cover the architecture of the flespi analytics system — there are a lot of interesting points that software engineers may take into consideration when working on similar projects.
My recommendation to a software engineer would be to start with a simple blocking on-demand reports calculation method, then migrate to job-based on-demand method within a year or two, and, after gaining enough experience on what your users need, start the implementation of a real-time pre-calculated report engine. Be prepared for a few iterations and at least one year of engineering work before you generate something usable. But once produced — this may be the most competitive feature of your product regardless of the type of system you develop.
The more challenging the task, the fewer competitors will try to copy it.