Analytics in flespi are time and budget-savvy. Initially released in 2019, it immediately paid off for its first user in the concrete mixers market with a 100x quicker and cheaper telematics data processing scheme. By the end of 2019, it controlled around 300,000 events. Nowadays, 4 years later, analytics monitors 1,700,000 various events from 750,000 telematics devices in real-time. From our internal statistics, I can clearly see that the level of analytics perception among flespi users is growing at a high pace.
We’ve got a lot of cases where companies initially use flespi at the basic level, primarily for data ingestion and occasionally for remote control. During the integration process, they discover that flespi is an incredibly transparent tool for troubleshooting and diagnostics. The next stage typically involves the need for telematics data transformation, which isn't achievable on the device's edge. If they encounter any problems and contact our support using the built-in chat, they find that flespi support is highly competent and effective in resolving their issues. Subsequently, companies often progress to automation and event extraction, leading them to flespi analytics.

At our flespi conference in Vilnius, I presented a general overview of its capabilities and primary use cases as a reporting and notifications engine. Over the last two months, following a spike in users, we released numerous system updates to cover various non-standard cases and enable our users to outsource all calculations they wanted to perform over the telematics data to flespi analytics. You can find detailed information about all these updates in the analytics changelog. In this article, I will provide a comprehensive overview of these updates and highlight typical use cases for various addons.
All analytics events are now annotated with a reason code
We made a significant step toward transparency in analytics by annotating all events generated by the system with an associated reason code. You can find the full list of reason codes in the REST API documentation.
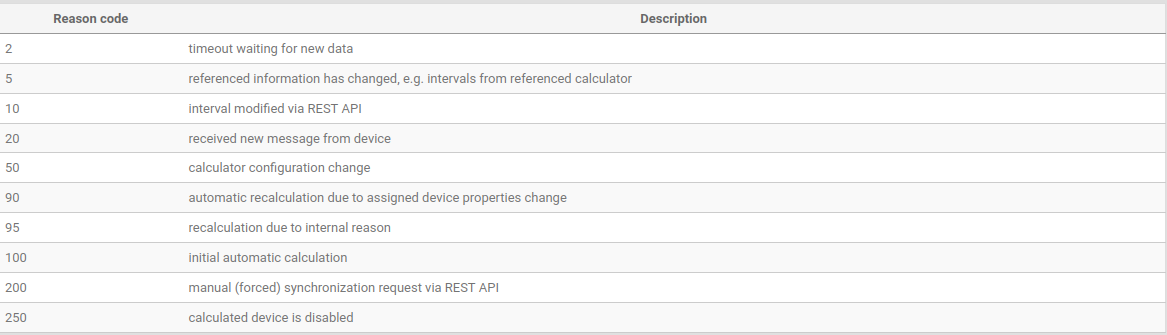
Now, when you look into the logs of calculators, you can clearly understand what’s happening, read the calculation state of the device and the reason behind each particular event. Along with a field in the logs, we also added the 'reason_code' user property to all MQTT messages published by the analytics system. This means that our users, if operating an MQTT 5.0 capable client, can now receive and check the reason for the event from analytics in their system as well.
The new capability to subscribe to topics with user properties-based message filtering is tightly tied to the update we introduced in the flespi MQTT Broker. It allows our users to apply these reason codes and minimize the amount of data they want to receive from flespi via MQTT, reducing network bandwidth or computation resources on their backend. For example, to skip all messages calculated during initial calculation when you assign a device to the calculator, use this filter:
user_properties["reason_code"]!="100"
To apply the filter, you should URL-encode it and insert it into the subscription topic in the following format:
$filter/message=URLENCODED-FILTER/ACTUAL-TOPIC
For example, to handle all interval events from all calculators, the subscription topic is flespi/interval/gw/calcs/+/devices/+/+. When you apply the URL-encoded filter above, your final subscription topic will look like this: $filter/message=user_properties%5B%22reason_code%22%5D%21%3D%22100%22/flespi/interval/gw/calcs/+/devices/+/+.
Intervals selector based on intervals generated by another calculator
This is one of my favorites among the new analytics features. It allows you to source intervals generated by another calculator into the interval selector and use them directly or in reversed mode. This significantly simplifies the whole calculator concept.
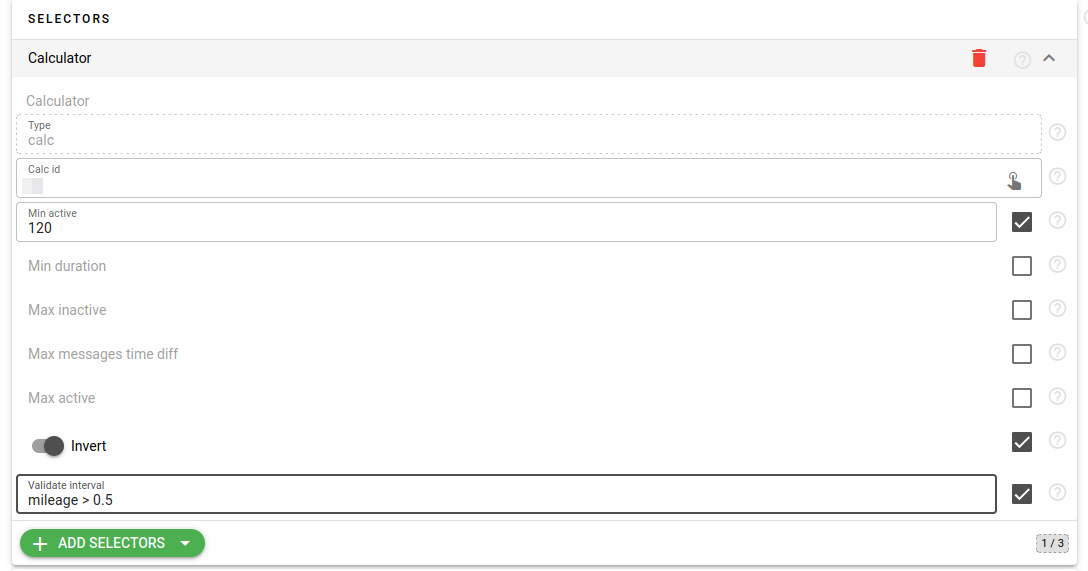
There are three major types of applications I see here:
Complex logic simplification
Reversed calculations
Extra calculation for the selected range of events
Let's begin with complex logic simplification. Imagine you have a highly complex algorithm to detect specific intervals, such as extracting trips and filtering out noise caused by GPS jumps. You need to calculate each trip using various counters based on the type of item, and you prefer not to mix this within a single calculator. Now, you can define your intricate algorithm (calculator) with its own set of counters using a dedicated calculator, let’s call it a trip detector. This trip detector marks device messages into corresponding trip intervals and can calculate actual mileage for each trip using various methods — CAN bus, device hardware, and programmatically with flespi — utilizing whatever is available for each particular device.
Next, you’d like to apply this trip detector and copy the calculated mileage into other algorithms that will present trip data differently based on the application type. Let's name these new calculators human trips, bike trips, bus trips, and so on. They source actual intervals generated by the trip detector calculator, along with mileage, and generate their own counters from this source data. If you decide to change your base logic for trip detection, you only need to modify it in one place — the trip detector calculator. These changes will automatically apply to all descendant calculators. Furthermore, this configuration provides a higher level of security, as you can conceal the actual algorithm and logic behind the trip detector with ACL, allowing users to access only simplified calculators with different sets of counters.
Reversed calculations are quite straightforward. You simply reference the original calculator in the selector and activate the 'reversed' option. Along with trips, you can get parkings based on trips. If one calculator calculates the work of an equipment, the reversed calculator generates corresponding intervals when the equipment is not working. The key point here is that you avoid replicating a reversed algorithm, ensuring that the reversed intervals always match the original ones without overlaps. So, each parking, except the last one, will always start and end with a trip. When using reverse mode, it's advisable to match the 'min_active' value to 'max_inactive' for both calculators to maintain maximum consistency.
Finally, performing extra calculations for a selected set of events allows you to determine all intervals in one calculator and calculate specific selections using various techniques. For instance, using trips as an example, one calculator detects all trips, while another calculator detects and calculates a selection of trips with detected harsh driving, displaying their drive score system. To implement this type of selection, utilize the `validate_interval` field in the selector configuration.
Maintaining and referencing the current calculation state
This is my second favorite feature. We defined a new type of counter called ‘variable’ which can generate and maintain the state during counters calculations. What's crucial is that you can access this state in all expressions while performing other counters calculations, and this state can be incrementally updated for each subsequent message. To access the value of such a counter within an expression, you use the function `counter(“name”)`, which returns null if no value is defined yet, or the actual value computed in this counter’s expression. Imagine you want to skip calculations for messages that fall within the first 30 seconds of an interval. To achieve this, you define a variable counter initialized with the time of the first message in the interval. Additionally, you set up a normal counter, which will start counting values only after 30 seconds from the beginning of the interval:
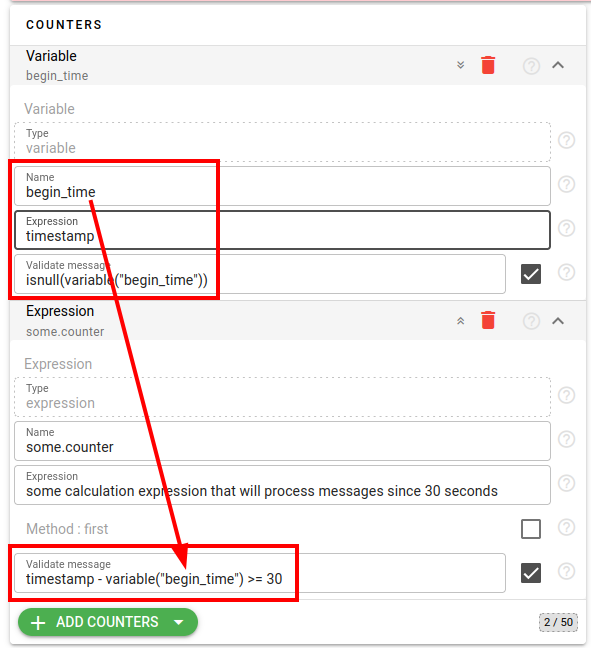
As you can see in the example above, you can even access the latest calculated value of the variable inside the counter that calculates it.
The possibility to maintain state during calculation provides you with almost scripting capabilities in flespi analytics. Importantly, the ‘variable’ type counter will not generate any output in the JSON of the resulting interval, making it a perfect choice for storing hidden values used in calculation logic.
Accessing intervals from another calculator in a counter
We enhanced a counter of type `calc` that allows one calculator to store intervals generated by another calculator, introducing two new options: `method` and `validate_interval` field. Imagine, once again, that you have a `stop` calculator to detect places where a vehicle was stopped. Now you can analyze these stops within the corresponding trip, detecting the very first or last stop based on specific conditions or selecting stops that match a particular filter.
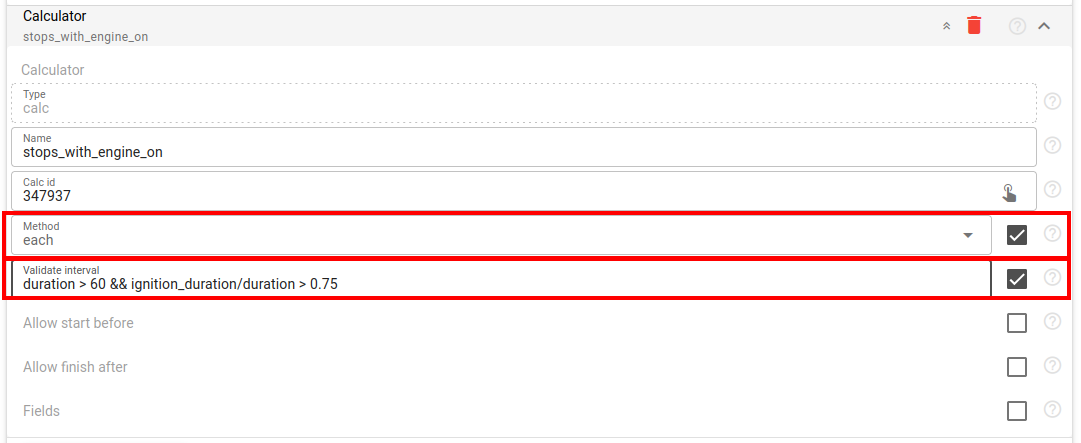
Supply only filtered messages to the interval selector
The last among the recently introduced options in analytics is the ability to filter messages before they are provided to the interval selector by utilizing the new `validate_message` field in the interval selector configuration.
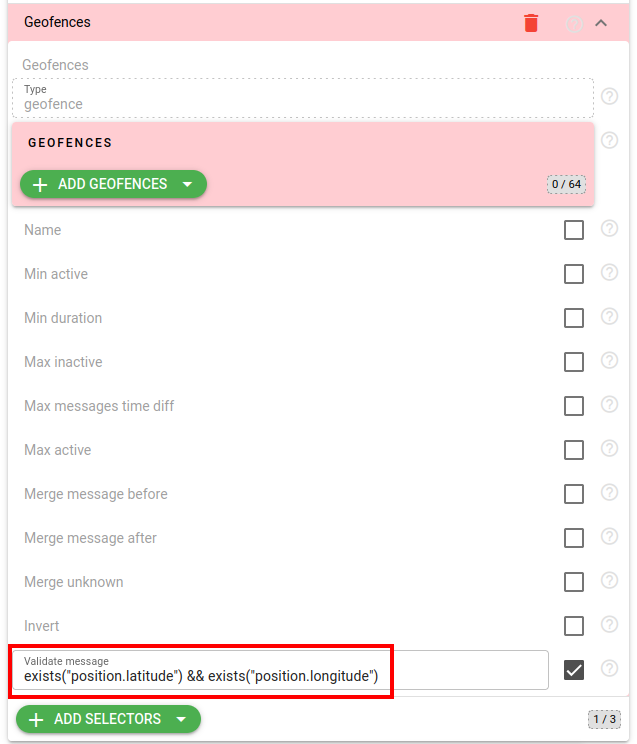
This new field provides you with precise control over messages that are fed into the interval selector and allows you to ignore messages you do not want to be checked.
We will continue to adopt flespi analytics for new tasks and applications, incorporating small yet significant improvements similar to the ones mentioned above. Due to its architecture, which is highly focused on processing telematics messages, our analytics system is unparalleled in terms of performance compared to any other engine. We are proud of this and are committed to making it even more robust to stay ahead of our competitors.