A few weeks back I explained three different approaches to report engine architecture — first is on-demand realtime, second is on-demand in the background and third is continuous background pre-calculation to be ready to serve report results immediately. flespi analytics is implemented with the third approach in mind. Let me explain its architecture and design ideas behind it.
To use flespi analytics you have to register a device on the platform and let it accumulate raw messages for some time, which is controlled by the messages_ttl parameter in the device settings.
The calculator instance defines the logic — i.e. what and how to calculate.
The actual calculation happens when you assign devices to calculators. These assigned devices are separate entities with own history of data precalculated in the background automatically as soon as either the calculation parameters change or the new messages arrive from the device. The storage period for precalculated data is defined by the intervals_ttl calculator parameter and can be much longer than the messages_ttl for devices. It means that you can store report results for up to 10 years while the raw messages storage can be limited to just a few months.
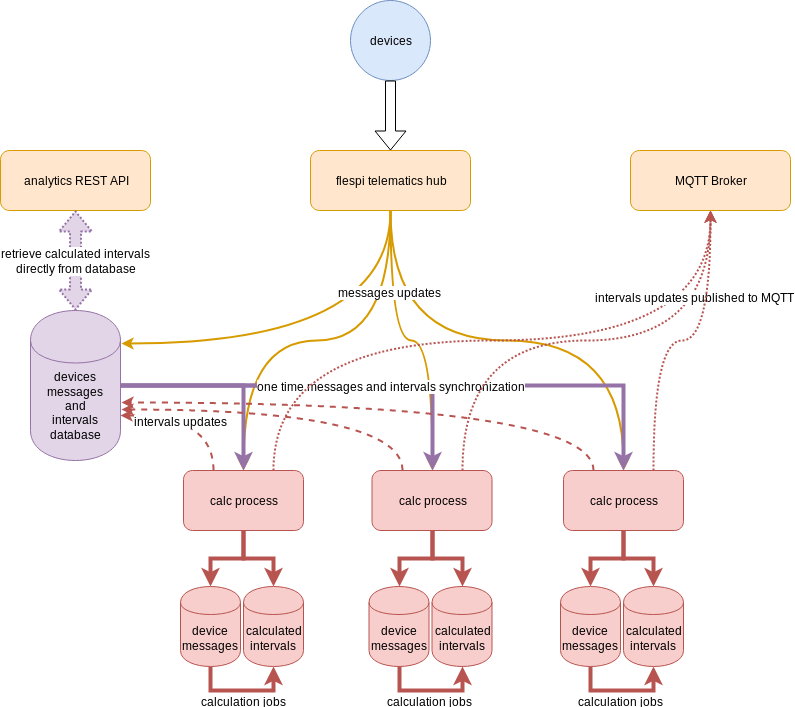
OK, so back to the analytics architecture. All devices in flespi are bound to one of the so-called calc processes, instances of which are running on multiple servers. Each calc process contains two local telematics databases powered by the flespi database engine — one for messages from devices bound to this process and another for intervals — calculation results for devices assigned to calculators. Each local device in the calc process goes through several stages:
unsynced — default state — we do not have a local cache for a given device;
synchronizing — this process can take a while, as all messages from the device are being copied into the local database of this calc process;
synced — all device messages are synchronized locally and being updated in real-time;
The default messages state for each local device is unsynced because if there’s nothing to calculate, then there is no need to synchronize messages. But once a device is assigned to some calculators and we need to calculate intervals from this assignment, we start the synchronization process for the messages. Depending on the size of the messages this can take from a few seconds up to a few minutes per device.
Then we repeat the same operation for the local intervals cache for each unique device/calculator pair. Once finished on the calc process, we have a fully synchronized copy of messages and intervals data for each particular device and can handle real-time updates.
When a new message from the device arrives, we specify a range for the recalculation and generate a so-called recalculation job for all device/calculator pairs involved. Each calculator contains the update_interval parameter that determines how many seconds to wait for further updates to enlarge this recalculation job range before its actual execution.
When the actual recalculation job is about to start, we check the time range and try to merge it to the closest intervals so that the range will be correct and recalculated intervals from the same source messages give the same result as we have in our storage. This is the trickiest part because we can have some device messages already removed due to messages_ttl parameter, some intervals can be far in the past and so on — a lot of variation to account for.
As the recalculation job is completed, we compare newly generated intervals with the existing ones and issue updates to the database, local cache, and to MQTT for external consumers. From this moment on the analytics engine is ready for the next recalculation job for this assigned device whenever needed.
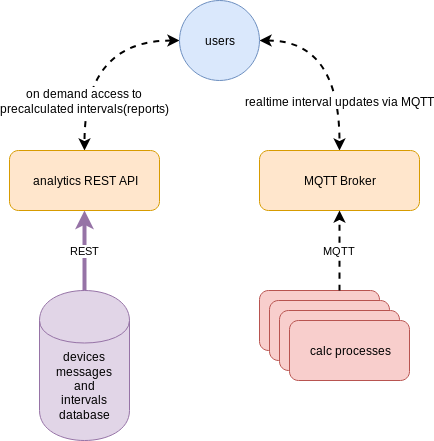
The key factors for the analytics calculations reliability and performance are based on the 100% local cache of the raw messages. It means that the flespi analytics engine does not need to query the primary database for messages. This approach is highly scalable on large data volumes. Whenever there is a change in the calculation parameters or incoming messages, we can recalculate reports instantly and always have updated data to be consumed by our users.
***
flespi analytics operates only with devices registered in the flespi platform. For those using telematics hub as a communication gateway (on a channel level) to speak to devices using MQTT and REST APIs instead of TCP/UDP packets, there is no need to register devices. Of course, it is possible to operate with flespi channels as a whole and store all received messages in your local database. In that way, you can run all reports over locally stored data which is rather quick and flexible. But usually at some point in time on large datasets from several GB to even TB of data you are likely to encounter performance issues. Even locally stored data on big volumes may be critically slow to calculate and the situation will worsen as your system grows.
To avoid potential slowdown and data unavailability, delegate report calculation tasks to flespi and enjoy its flexibility and performance.