If you have one server and a couple of processes running, it is simple to administer them. But what if you have dozens or even hundreds of servers each hosting dozens of services? And what if servers are spread across different datacenters? How to administer them all efficiently?
When we started developing flespi platform we had a good knowledge of Wialon Hosting administration. There we grew from 3 servers up to 200 in 7 years. It's not that easy to manage such a big number of servers, especially since on top of that you need to deal with tons of applications running on them. You need to install updates, configure applications, control their functional parameters, perform load balancing, etc. It is impossible to orchestrate without special automatic tools with bots controlling what's going on with the cloud. In terms of monitoring software, it's quite easy to find a solution and tune it — for example, using zabbix, monit or any other standard Linux monitoring tool. But if you need a bot to automatically do some important administration tasks — for example, switch gateway between active/passive mode, switch databases between secondary/primary or even stop/start some applications — you need to develop the logic by yourself and exercise great caution. Further, I would like to share the architecture of our automatic services monitoring, configuration and administration solution.
From a bird’s eye view, flespi cloud consists of locations (datacenters), servers and services (applications). Consider reading the basic overview of flespi platform architecture before proceeding.
Infrastructure
Infrastructure in each datacenter consists of high-level failure-proof servers of three different types:
- app — application server. Quad Core Intel Xeon E3 CPU, 32GB RAM, 2x200GB SSD in MD RAID-1;
- db — database server for hosting up to 6 MDB nodes. Quad Core Intel Xeon E3 CPU, 64GB RAM, 2x200GB SSD in MD RAID-1 and 6 separate 2000GB SATA drives;
- archive — special purposes servers used for storing big data logs, backups, etc. Quad Core Intel Xeon E3 CPU, 32GB RAM, 2x200GB SSD in MD RAID-1 and 16 4000GB SATA drives in RAID-6 providing 51 TB of continuous storage space;
Additionally, two similar servers are dealing with traffic routing and connectivity between datacenters. These are managed by a pacemaker and duplicate all installed services. In a normal situation, one server handles all gateway/connectivity services via iptables/IPVS and the other server takes care of all LAN services including hosting of our ADMIN system for automatic services management and zabbix for monitoring servers and services state and load.
Since we are using the same server configuration it is easy for us to replace faulty servers and order new ones. Standardization is really important when you operate hundreds or even thousands of servers. You don’t need to think which server configuration to order, just perform all investigations and hardware configuration tests in advance and then refer to the results repeatedly.
By the way, all our applications are greatly tied to the infrastructure architecture — they are designed and configured to operate with this special servers configuration keeping in mind CPU, storage available, disk IOPs and OS possibilities. We are using the latest stable version of Debian as an operating system.
Currently, we are operating only one location — we call it tcn and actually it is TCN datacenter in Groningen, Netherlands. We are planning expansion to other locations on different continents as we would like flespi cloud platform to be globally uninterruptible. However, new datacenters are to be added no earlier than in 2018.
Applications
All applications — we call them services — are developed by us in pure C language and most of their components are authored by us — even durable IPC, HTTP client/server and of course configuration system. Configuration system is quite simple: upon startup, each flespi service is retrieving configuration via an HTTP call to configuration server and then operates based on this configuration. Before I continue, let me describe our centralized configuration service, so-called ADMIN service, the heart of the system.

ADMIN system contains information about all services and servers in flespi cloud and provides a possibility to manage services via REST API: build versions, install services to specified hosts, upgrade and downgrade their versions, start, stop and check services, even activate embedded lua script interpreter and run some debug actions on the running process.
Each service has one of the predetermined types, for example for flespi gateway we use tg to work with connections, tgctl to provide REST API, and tgstm for streaming. For flespi database system, we use mdb for database nodes and mdbctl to provide nodes control and REST API services.
Each service type contains associated configuration information in yaml format. This configuration specifies how and where to install or uninstall service, any dependencies to server or availability of other services in the cloud, and any additional configuration for other services if there are other instances of a given type. For example, mdb configuration looks like this:
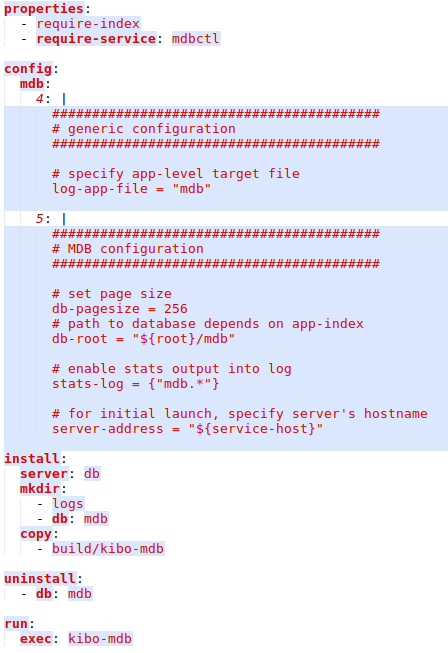
I will not dive into details, just want to give a few highlights: require-index means that each service instance on the server will be assigned unique index available later in the configuration under ${app-index} variable. Special db label in install/mkdir section means that on a db server containing 6 separate SATA drives mounted at /mnt/drive1.../mnt/drive6 directory one of these mounted directories will be used as a target for symlinking mdb directory. And all database files will be placed in mdb directory relative to service path. Also, uninstall section specifies any additional cleanup needed at the service root directory — in the case above it’s the database directory on a mounted drive. It may sound complicated, but actually, it is quite straightforward. And whenever we need something additional we can easily implement it.
The config section in the middle of the file specifies actual configuration components for services of mdb type. They are sorted according to digital sort-order to correctly combine configurations from multiple sources. Each configuration file can have a config section.
Multiple configuration files may affect the final configuration, because they may contain config blocks for the same service. For example default so-called fake configuration files contain common settings:
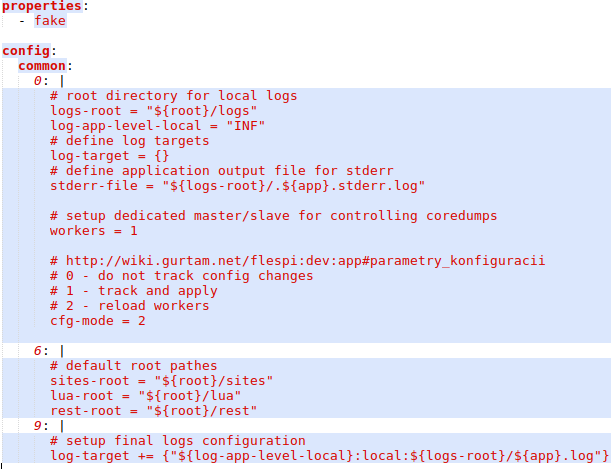
Here the special fake property means that we should use this configuration file even if we do not have a service of this type. If this property is not set, then meta-configuration file will be applied only in case at least one service of the specified type exists. Default configuration contains all settings required to setup logging into local files.We also have a special service called logger that can receive and store logs from all flespi applications. It’s meta-configuration looks this way:
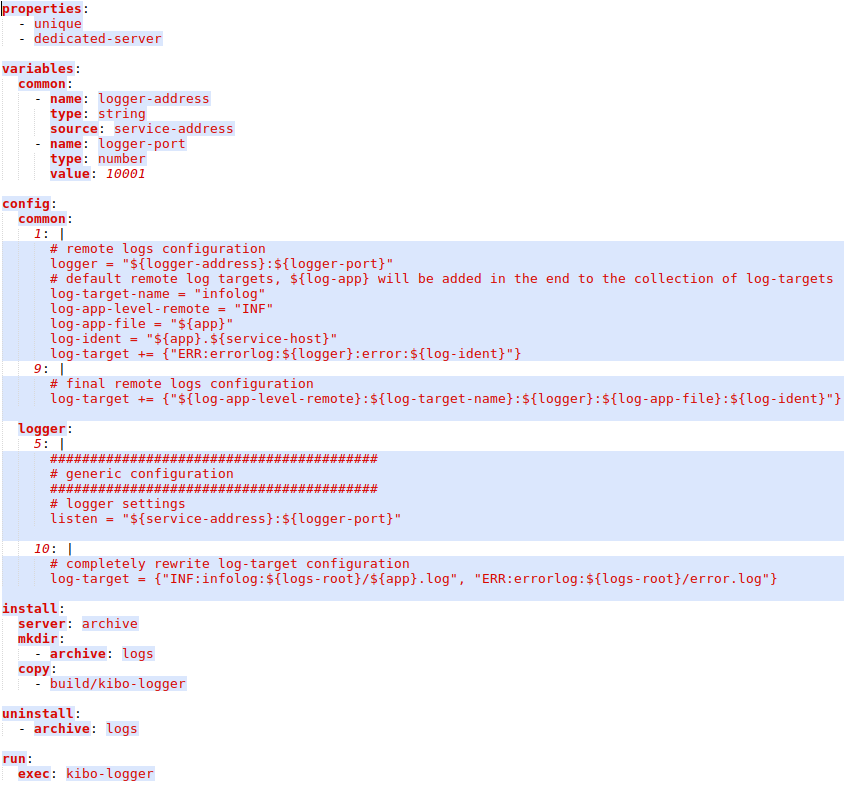
Notice a special unique property meaning that only one instance of a given service can be created in the cloud. For all services within a common block, logger adds own addresses for remote log target. In the end of own configuration, it completely rewrites logging, because it can not remotely log to itself. You can also mention special archive keyword in install section — it has the same meaning as db in db-type servers, but for using common /mnt/archive as the base directory for logs. On archive-type servers /mnt/archive is mounted to RAID-6 with tens of terabytes of the storage.
Finally, I would like to show you how combined configuration file for mdb service looks like:
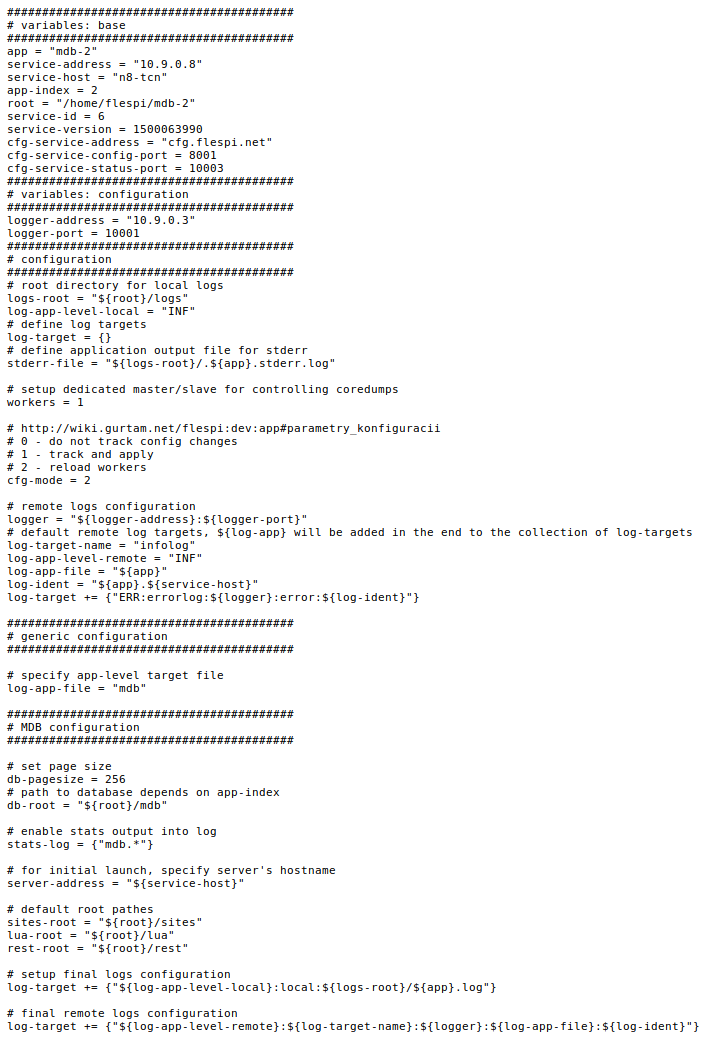
I understand that we have already dived really deep into the configuration description, but I just want to show you how powerful and flexible our embedded configuration system is. It’s just a part of the cloud, but it helps us a lot and makes DevOps work quite simple and clear.
So, let’s continue. Each service fetches configuration from the ADMIN service via HTTP and parses it. One very important configuration option is a workers keyword. It specifies the number of workers to fork. Zero value means that we should not fork anything and continue with one process. Values from 1 to 4 (usually) mean that one process will be used as a controlling master, that does nothing but forks itself into separate workers, checks configuration changes and workers statuses, performs debug dump and restarts them in case of failure, and establishes direct link to ADMIN service to allow it to receive all notifications, detect and report unexpected control connection failures, and, of course, perform remote management.
Some processes contain only one worker, like mdb — because it deals with database files and is restricted by drive performance. Other processes (most of them) want to be forked four times — each worker per CPU core. All our TCP/UDP connections listening services are bound with SO_REUSEPORT socket option for Linux kernel to automatically distribute new connections between all workers.
Workers and fork options allow us to completely avoid using threads and thus simplify and optimize applications architecture.
If something is happening to the process, we pause the worker process inside the signal handler and master process can automatically detect such situation, perform gdb dump of the current worker stack with variables into a file, kill and restart it, and even report to ADMIN process, which logs this situation and generates notification into our flespi SRE Telegram group.
To catch wrong memory use we also compile and install some services in a debug mode. In this mode, we link an application with an address sanitizer. Although requests processing in such configuration is quite slow, it enables us to detect any memory-related developer errors quite easily.

Before issuing updates in ADMIN system we build versions. Version usually contains a full set of files that the service requires, including both compiled binaries and all the resource files. Now that we have versions, it is quite easy and straightforward to upgrade services to the latest version or even upgrade only a couple of services to perform metric tests if needed. Downgrading to the stable version is equally fast and effortless.
Versions management allows us to minimize time on local testing and install patches and updates to production system quite often. Our experience shows that for any cloud system the production environment is the only real check for bugs. All testing environments usually lack the correct load factor and thus are not really usable.
By the way, for automatic quality control, we not only run full cycle remote tests, service meta-configuration file can also declare some internal tests procedures. For example, here is how pgw (proxy server for PROD subsystem acting as the main entrance for REST API requests from customers and proxying them into local systems) looks like:
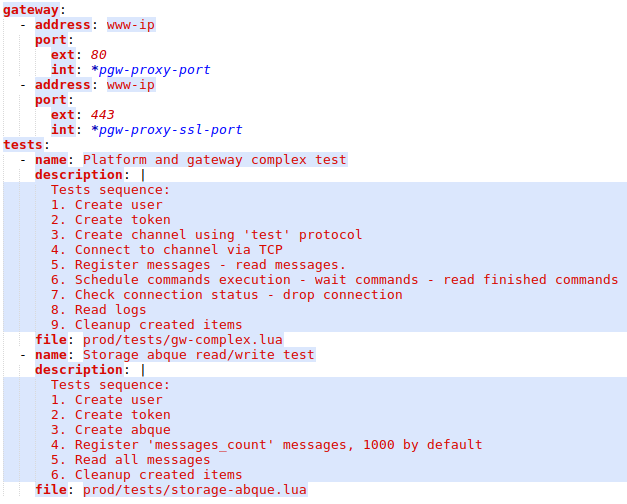
As you see we have two automatic tests and upon each upgrade, we run them to ensure everything works as expected.
Services export
And last, but not least is our firewall configuration. It is also managed automatically via ADMIN service. Each service willing to export any of its ports outside of the cloud contains a special gateway section in the meta-configuration file. For example, pgw service from the screenshot above indicates that it wants ports 80 and 443 for the www-ip address to be forwarded to the service’s internal port. www-ip in the main TCN datacenter is 193.193.165.36 or just flespi.io.
And if we look into tg meta-configuration, which role is to receive connections from devices, we see a little different structure for the gateway:
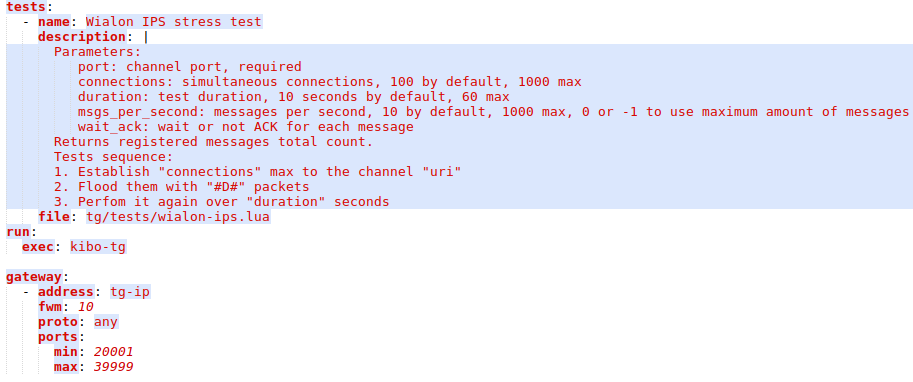
It contains a special fwm construction that means firewall masks will be used to catch a range of ports and serve multiple tg-ip IP addresses.
On the gateway side, every 3 seconds cron process automatically downloads configuration of services in CSV file that contains what external connections are allocated to which internal addresses and ports. In case of any changes, say we put one service node out of production or migrate service to another server, iptables rules and IPVS configuration are regenerated and activated.
Database management
During active development, you often need to change database schema for some applications — add new columns or even new tables. Initially, we patched databases manually, but later we decided to do it automatically via the same ADMIN system because it knows the database connection string and can even perform database installation from scratch or apply multiple patches incrementally.
Now databases management is very simple — we can just tell ADMIN system that it should check if databases for specified processes are patched and if not, patch them automatically. Although database patch operation is one direction only, after patching it is difficult to downgrade the service to an older version that expects different database schema. That’s why we try to change database schema carefully and only when we really need it.
Scripting
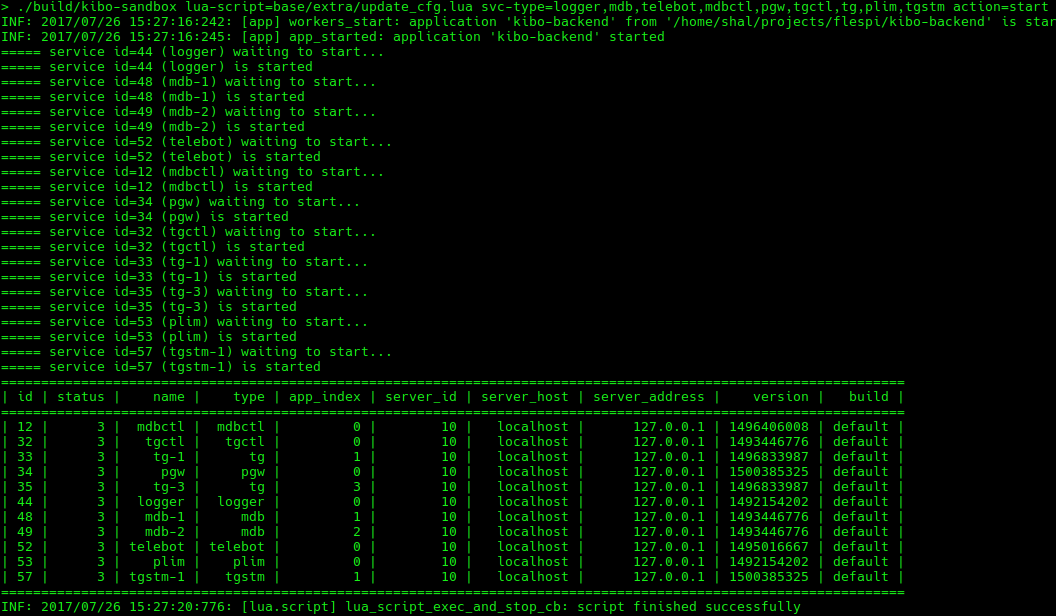
Although all services and servers management operations are available via REST API of ADMIN system, we developed a script that simplifies these actions. For example, starting a full-featured flespi cloud on a local system is as easy as this:
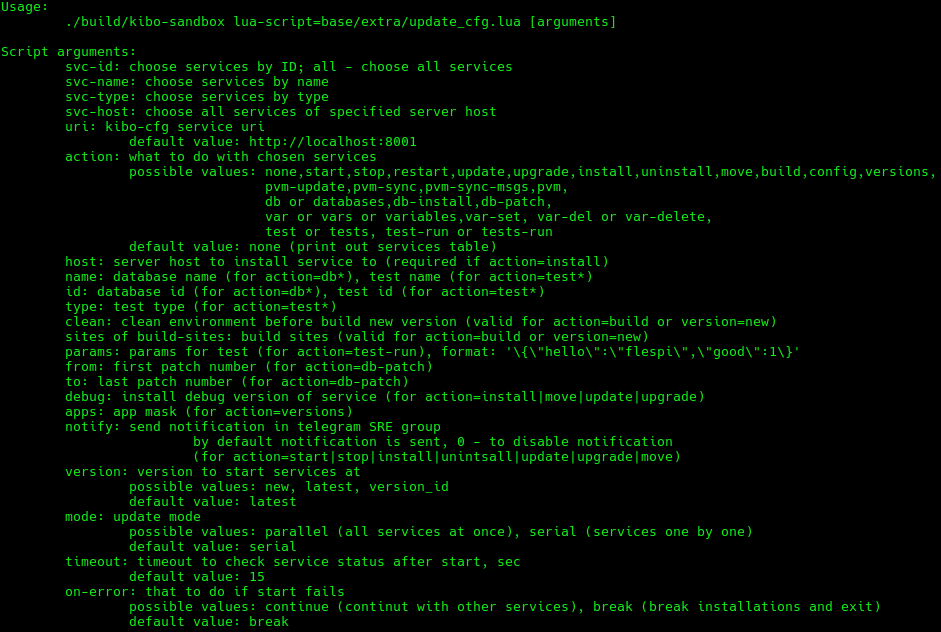
And here goes the full list of parameters for this script, just to give you an idea about it:
Everything works quite smoothly and reliably and does not require any attention of system administrator under normal circumstances. Although flespi cloud itself is quite young and we do not really have much load at the time, we designed this architecture to scale fast and easy in the future.
We can share some insights on iptables firewall or ipvsadm rules as well. Please contact us in case you want more explanation about any of these systems or need in-depth technical information about the flespi cloud.