There are always subjective pros and cons for every approach in development. At flespi, we don’t hypothesize; instead, we conduct real-load tests to determine the best option.
The main idea in my conference speech about flespi integrations was to try MQTT. Indeed, when considering the task of live event updates from flespi, MQTT API beats both REST API and streams (in fact, the main battle being between MQTT API and streams).
In my previous article about consuming flespi messages via HTTP stream vs AWS Lambda function, I’ve achieved a remarkable throughput of 42K messages per minute. So, I decided to check if MQTT API can outcompete this use case.
Environment and task setup
During the presentation, I discussed the paradigm shift from the request-response model used by streams to the message broker idea.
While an HTTP stream receiver can be run as a Lambda function triggered by a request, an MQTT client works continuously. Thus, it requires an environment where the processing script can operate uninterrupted.
Moreover, the MQTT client does not need Lambda’s public URL to be invoked by the stream because it establishes a connection to the public URL of the message broker. Therefore, the best choice to run the script is an EC2 instance (or any other virtual machine of your choice).
I chose the smallest available instance, t4g.nano, with 2 cores and 0.5GB RAM. The task is the same as with the HTTP stream + Lambda case: receive parsed messages from flespi and push them to the AWS SQS queue.
Results
This time I’m aware that the main limiter might be SQS itself, with its synchronous requests processing. So, I know that requests to SQS must be a series of packets with 10 messages in 1 request. What’s more, as I now have a server in the same datacenter with SQS, I may now measure the SQS limitation as well.
The simple script with a static flespi example message (an average message with 32 parameters, 700 bytes long JSON) packed 10 times and delivered to SQS through the simple boto3 SQS.client.send_message_batch() function in an endless loop resulted in 44K messages per minute.
Essentially, this is the higher limit of Lambda or a single script on EC2. With 42K messages per minute for AWS Lambda, it seems that the main limiter for the HTTP stream was SQS latency, as 95% of Lambda time was taken by SQS import, while only 5% was for accepting and parsing data from the HTTP stream. Shame on me that I did not check it earlier.
The same situation was expected when I tried to run a Python script that subscribes to messages over MQTT and packs them in 10-item batches and sends these batches to SQS. And this is exactly the result achieved with a single script: 42K messages per minute. Thus, it’s fair to say that both HTTP stream and MQTT API received 3 out of 3 stars in my rating.
That’s not all. My EC2 instance loaded only 1 core for 33%, which led me to the idea of verifying some other parameters, specifically “scalability” and “low integration effort”. With 33% load and 2 available cores, I could run 6 scripts simultaneously.
The two things I changed in the script were: MQTT client id to be unique, and I added “$share/my_test_group/” in the subscription topic so 6 scripts would get messages from the same subscription using the shared subscription load balancing technique. This resulted in 6 workers running on 1 virtual machine, each loading 1 core for 27%, and processing ~30K messages per minute…
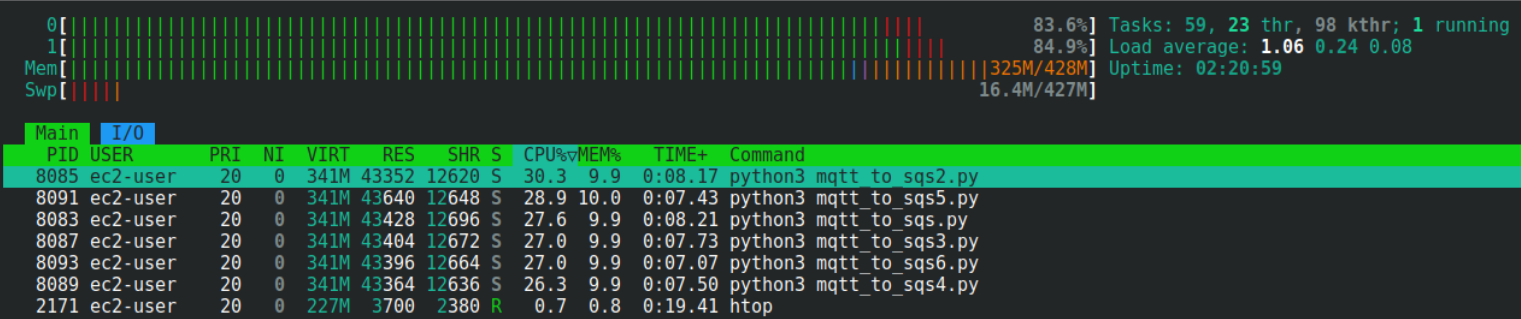
…and that gives us a result of 180K messages per minute for this smallest EC2 instance. Surely, something similar could be achieved by creating an extra HTTP stream, duplicating AWS Lambda function, and reassigning part of the devices to the new stream. But obviously, it would require more effort.
Prices
Without going into deep details: t4g.nano costs ~0.005 USD per hour, giving a monthly price of 3.6 USD. There's no extra charge for MQTT sessions, and the throughput of 180K messages per minute from the flespi side results in 2 USD per 100K messages per minute throughput.
If we assume the following:
Lambda function is active 99% of time (because the stream would send the next batch of messages as soon as Lambda confirms the delivery of the current batch).
Memory use in my case never exceeded 128MB (lowest price for execution 0.0000000021 USD per ms).
Number of requests is 42 per minute, resulting in 1.8M requests per month (0.20 USD per 1M requests).
The price for Lambda usage would be 5.8 USD/month, which gives us 13.8 USD per 100K messages per minute throughput. If we add here 20 EUR/month for the flespi stream to get 26.85 USD per month for 42K messages per minute setup, it will make 64 USD per 100K messages per minute throughput. The price for MQTT API usage is from 7 to 30 times lower than HTTP stream plus lambda.
Conclusion about how useless this article is
Actually, I have to admit that this article is written mostly for fun. Why? From my architectural perspective, all the analysis of flespi messages must be performed by our analytics engine.
You should consume not the full load of parsed messages but extracted sublimed data of business events that make sense for your case (trips, refuels, geofence exits, idling, harsh driving, temperature violations, CAN bus codes, overspeeding, etc.) In short, optimizing heavy calculations on flespi would save you much more money than optimizing throughput on the target system.