April 2025 was a crazy month for flespi.
The month started with a terrible datacenter blackout. Luckily, we operate two data centers in parallel, so there was no data loss. While some users experienced increased latency in message delivery during the recovery period, the most critical operations remained functional.
Still, it took time to bring the affected datacenter back online, and due to the spike in load, some internal components were slightly overloaded for a while. You can find the detailed incident report here, but the summary is:
Our monthly uptime in April 2025 dropped to a historical low of 99.7792%.
We walked away with a lot of lessons and some unique experience.
We shifted our priorities and have already made a number of important changes to the internal platform components to make them work better in case something like this ever happens again.
We proved that our dual-datacenter setup is durable and fault-tolerant.
When incidents like this happen, it’s a kind of life-or-death scenario. In a flash, you see what’s black and what’s white – and what really matters. We had recently pushed a bunch of new features in flespi and started to deprioritize refactoring and ongoing internal improvements.
Nobody notices months of internal work if nothing changes on the surface. Sure, things might be more stable, better structured, and beautifully architected underneath, but if users don’t see any difference, who knows if that work brought real value? Well, until something breaks. Then you either survive it… or you don’t.
That’s exactly what happened to us. Right after the incident, we brought refactoring and internal improvements back to the top of the list, giving stability a higher priority than feature delivery.
With all that said, it doesn’t mean we had underinvested in internal optimizations before. Not at all. From day one, we’ve been actively improving the flespi internal architecture and mapping software layers to make the most of the underlying hardware. But it’s always been a point of debate in our team meetings –the same question over and over: do we really need to spend so much time on things nobody can actually see? And since the incident, we’ve got a solid “yes” to that – no more discussions needed.
Post-incident architecture improvements we were focused on pushed back the development of the new assets functionality by a few weeks. Initially, we planned to release it in analytics by the end of April, but now it’s moved to May. We’re actively working on it – stay tuned to the analytics changelog.
Once we started working with DTC codes from various sources outside of the LCV and personal vehicles industry, we quickly discovered that simple textual code representation is way too limited. To handle this, we announced a change in the can.dtc parameter representation – from string to object – with two temporary parameters registered for a month to facilitate the transition: can.dtc.strings and can.dtc.objects. The transition of the can.dtc value format will be performed on May 8, 2025, and the temporary parameters will be removed on May 24, 2025. Please look here for details and adopt your integration.
A lot of work has been done on the tacho functionality. We have a huge demand for this from European TSPs, and actively improved the support of legacy devices, which often do not comply with modern protocol specifications. However, with hundreds of thousands of them installed in vehicles, nobody will ever bother to adopt or upgrade the firmware, and we’d better improve their handling on the flespi channel side. At the moment, we are adopting our open-source Tacho Bridge App to support Stoneridge tachographs authentication.
We were also consistently improving video telematics integration across most of the supported protocols. Engineering teams from several manufacturers are working closely with us, updating their firmware on a daily basis. This, in turn, pushes us to regularly adapt our server-side implementation within the protocol. Still, the progress in this direction is clearly visible. We’ve added a controlling switch in the device configuration for automatic event photo/video download for all protocols that support this feature.
In April, codi, our AI assistant and flespi teammate, leveled up. It now proactively participates in chat discussions, with the ability to schedule and carry out additional follow-up actions, such as updating users on ongoing issues, tracking their progress and account status, escalating matters to the team, or simply sending a friendly follow-up message. This kind of engagement, where the AI decides when and why to act for a specific user (with the decision framework pre-programmed by humans), takes its operation to a whole new level. Below are examples of follow-up tasks codi sets for itself while working with our users and resolving their inquiries:
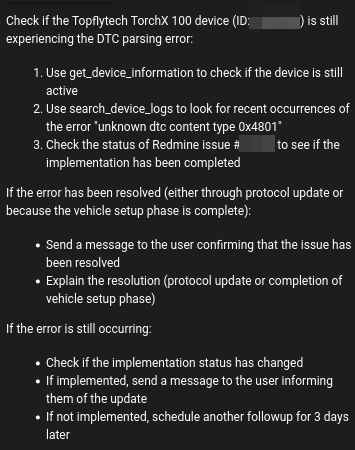

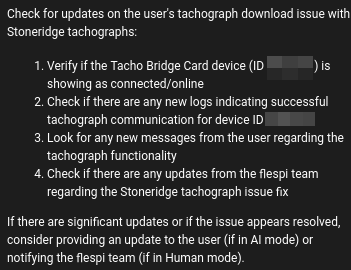
As you can see, this is far from a simple, dummy follow-up task. It's exactly what you’d expect from an actively engaged company employee. Often, codi tracks user progress in the background and, if issues persist, will pop up and escalate the matter to the flespi team.
The quality of codi’s responses and actions, in line with the decision framework, available tools, and provided knowledge, has reached a level where it consistently outperforms the human assistant in most tasks. This significant progress has also impacted our support process, with increasing focus on enhancing codi’s capabilities and improving its performance in edge cases. Additionally, codi now self-improves by automatically extracting knowledge from conversations, continuously updating its decision framework and knowledge base in real-time.
This makes codi a powerful and reliable consultant for any telematics-oriented project, but keep in mind that its focus is still primarily on flespi. To broaden its scope, we’ve also integrated codi with its counterparts from Gurtam – Wialon AI Assistant and GPS-Trace’s Tracy – enabling it to generate responses when serving our users. We are also considering expanding codi’s knowledge to include other connected platforms, aiming to make it a single access point to the most powerful technical consultant for telematics.
At the same time, the focus on quality that we’ve placed on codi has had an impact on its latency. It becomes slower at certain times when it needs to gather all the information for its reasoning. This contrasts with the expectation that an AI agent should instantly produce an answer, which is common with ChatGPT and other modern chatbots. However, just like with people, data-driven decisions require time to gather and analyze. Our choice between speed and quality is quite clear, much like the balance between new features and refactoring I mentioned earlier in the article. We are committed to the quality of AI responses just as much as we are to the stability and durability of the flespi platform – and nothing can compromise that. New platform features and quick AI responses will follow.
In May, we will continue progressing on most of these fronts: tacho, video telematics, AI, complex systems development, etc. And I believe we’ll have a few updates related to direct OEM integrations.
Stay tuned!